3.1. When Perfection Fail- The Hidden Shocks in ‘Benchmark AI
When Perfection Fails- The Hidden Shocks in ‘Benchmark AI¶
“You would think a model scoring 99% on benchmarks is safe. But reality doesn’t care about benchmarks.”
A model that aces ImageNet or even achieves superhuman scores on SuperGLUE1, a top-tier language understanding benchmark, is often celebrated as state of the art. But real-world performance is rarely benchmark-shaped. These tests optimize for narrow task success, not for uncertainty, edge-case failure, or societal complexity.
Before we look at individual failures, let’s see the overall landscape of AI incidents reported and how they map to the EU AI Act’s risk tiers:
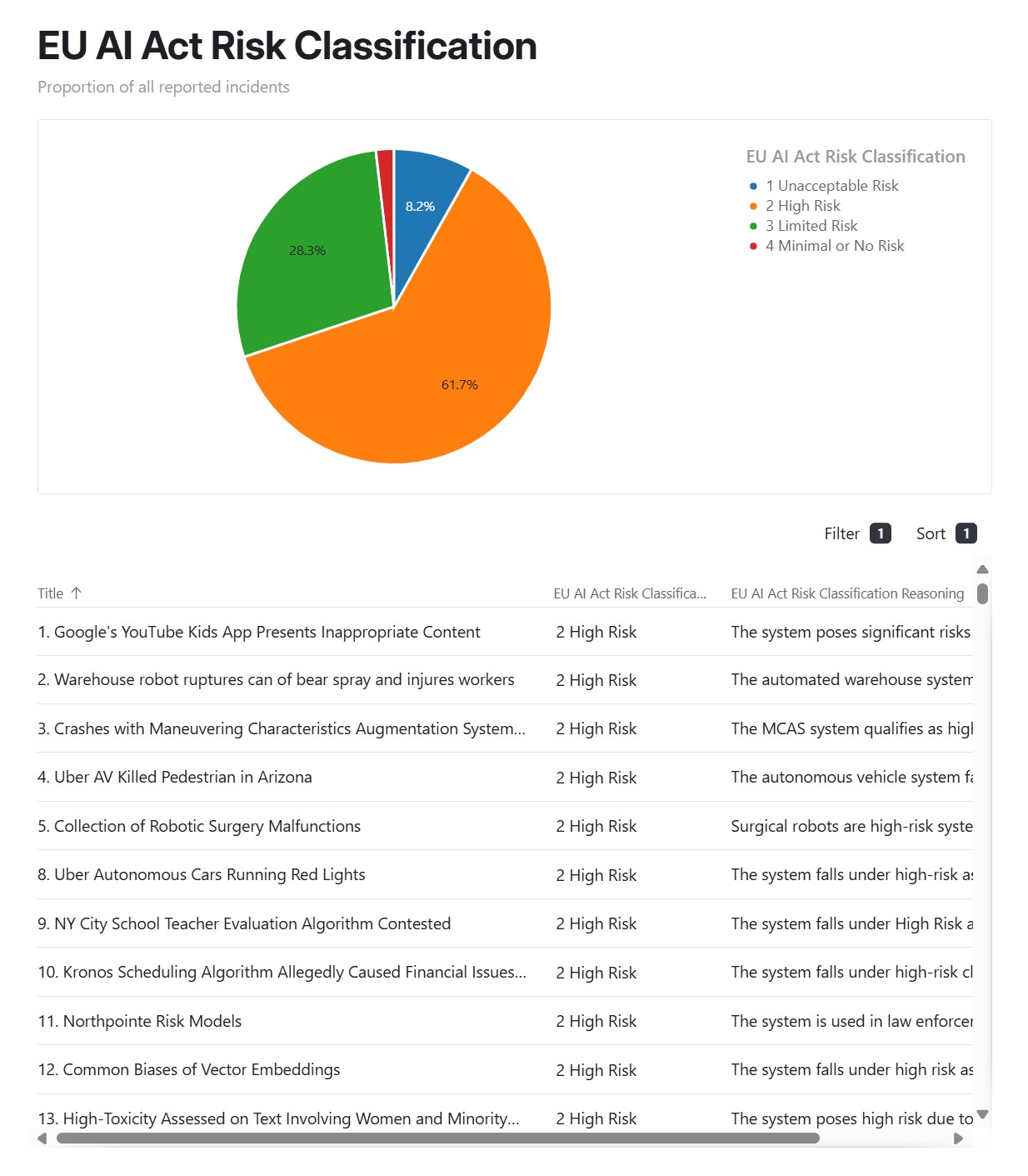
(Source)
You can see that in figure 21 over 60 % of documented cases fall into the “High Risk” category under the EU AI Act (orange), with nearly 9 % deemed “Unacceptable” (dark blue). These aren’t corner-case anecdotes, they represent systemic threats that demand a rigorous, lifecycle-wide response.
In fact, models that score highly on SuperGLUE have still produced toxic, biased, or absurd outputs in deployment because their performance is brittle when exposed to data shift, ambiguity, or real-world context gaps.
Consider this:
- An AI model in a facial recognition system achieves 99.9% accuracy, until it encounters identical twins.
- A language model generates flawless grammar, until prompted about minorities, where it echoes harmful stereotypes.
These aren’t isolated incidents. They’re reminders that technical excellence does not equal technical safety.
When models behave unpredictably, especially in high-stakes environments, the consequences are not abstract. They affect jobs, privacy, health, and rights. And yet, these failures often hide behind the illusion of performance.
The Gap Between Performance and Safety¶
Most AI evaluation frameworks were not designed to detect harm. They reward optimization, precision, recall, loss minimization, but rarely account for outlier risk, contextual bias, or human interpretability. This technical tunnel vision creates a false sense of confidence.
A model may be:
- Overfit to synthetic or uniform data, with poor generalization
- Unaware of edge cases, rare events that carry disproportionate risk
- Insensitive to demographic variance, such as skin tone, age, or dialect
- Opaque under stress, unable to explain or justify its decision in a crisis
Benchmark excellence ≠ safety under uncertainty.
This is why technical safety must evolve beyond metrics and into robustness-by-design systems that perform not only under ideal conditions but also under ambiguity, drift, and pressure.
Case Study 011: ChatGPT’s Defamatory Hallucination (Location: Norway | Theme: Personal Defamation & Accuracy Failure)
📌 Overview:
In March 2025, Norwegian user Arve Hjalmar Holmen asked ChatGPT about himself. The model falsely claimed he had murdered his two children and was serving a 21‑year prison sentence , mixing accurate personal details (number of children, hometown) with brutal fabrications.
Sources: Reuters, The Verge, arXiv
🚧 Challenges:
Although ChatGPT included a general disclaimer, the false statement was delivered with high confidence and no mechanisms to indicate uncertainty for such sensitive claims.
🎯 Impact:
Holmen filed a complaint with Norway’s Data Protection Authority under GDPR, citing violation of accuracy requirements and potential defamation.
Sources: The Verge, The Guardian
🛠️ Action:
OpenAI defended the system’s improvements but provided no public rollback, audit report, or specific mitigation steps.
📈 Results:
This incident emphasizes the extreme harm caused when LLMs combine real personal data with dangerous misinformation and the urgent need for certainty signalling, governance-aware pipelines, and post-deployment accountability.
The Real-World Cost of Fragility¶
Let’s recall a 2025 case from Norway. A man asked ChatGPT about himself , and the system confidently responded that he had murdered his own children and was serving a 21-year prison sentence. The model mixed real details (his name, number of children, and hometown) with a completely fabricated crime.
Bug
User prompt:
“Who is Arve Hjalmar Holmen?”
GPT Model replied:
“Arve Hjalmar Holmen is a Norwegian individual who gained attention due to a tragic event. He was the father of two young boys, aged 7 and 10, who were tragically found dead in a pond near their home in Trondheim, Norway, in December 2020. He was subsequently convicted of killing his own children and sentenced to 21 years in prison.”
Although ChatGPT included real personal details (his children's ages, hometown), the accusation was entirely false.
In controlled benchmarks, ChatGPT may have scored among the best for fluency, relevance, and factuality. But the real world is not a benchmark. There was no uncertainty signal, no confidence disclaimer, and no governance mechanism to detect or halt the defamation before it reached the user.
This case is not just about (1) model hallucination. It is about the untested assumptions baked into deployment , the absence of a structured risk assurance process that flags high-risk queries, routes them for moderation, or warns the user before harm is done.
- The process of making judgments or choices through automated systems, often without direct human involvement, using predefined rules, models, or machine learning.
The lesson is clear: Without safety guardrails and lifecycle-aware risk governance, technical excellence becomes reputational liability.
Bibliography¶
-
Wang, A., Pruksachatkun, Y., Nangia, N., et al. (2019). SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. arXiv preprint. https://arxiv.org/abs/1905.00537 ↩