3.2.1. Introducing the AI Risk-Lifecycle Framework
Introducing the AI Risk-Lifecycle Framework¶
"What testing is to software, risk governance is to AI. One happens before deployment. The other must happen before, during, and after."
To move beyond benchmark illusions and into real-world safety, we introduce a unified governance architecture: the AI Risk-Lifecycle Framework. Built on ISO 31000, ISO/IEC 23894, and the NIST AI Risk Management Framework (RMF), this five-phase model turns abstract ideals into operational safeguards.
The framework consists of five continuous phases, Map, Measure, Manage, Monitor, and Improve, each guiding how AI risk should be identified, tracked, and mitigated across the system’s lifecycle as shown in Figure 23
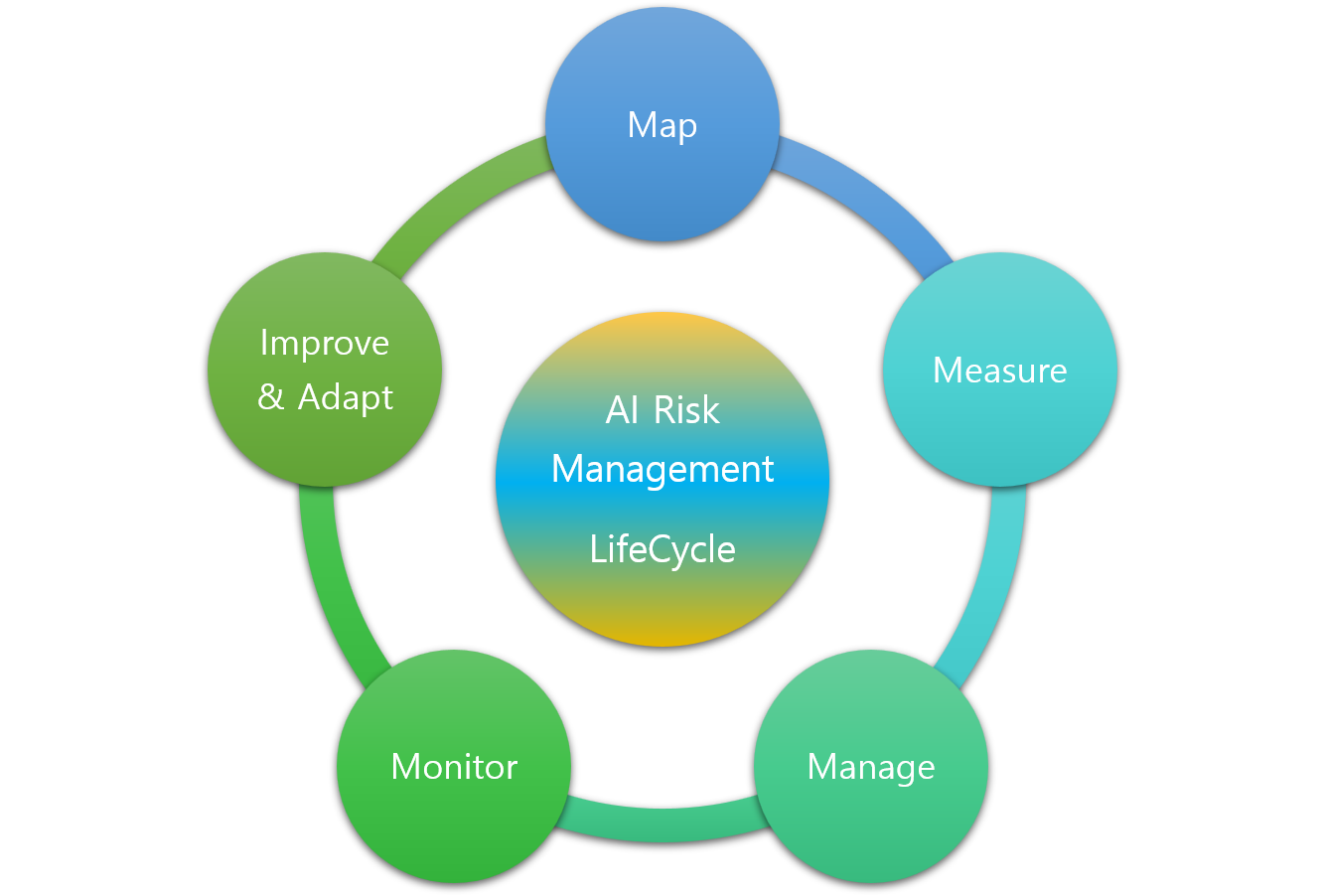
We demonstrate how each phase works through a realistic simulation: EqualMatch.ai, an AI-powered job-matching platform built to improve hiring outcomes for underrepresented communities in tech and design. Though ethically motivated, the system, like many others, can still fail if risk isn’t structurally managed from the beginning.
Ethical intent is not enough. Risk must be traced, tested, and treated across the lifecycle.
AI Risk-Lifecycle Phases & Standards Alignment¶
Table 15: Five Phases of Risk Governance
| Phase | Objective | ISO 31000 | ISO/IEC 23894 | NIST AI RMF |
|---|---|---|---|---|
| 1. Map the Context | Define risk boundaries and operating conditions | Clause 6.3 – Scope, context and criteria | Clause 6.3 – Scope, context and criteria | Map |
| 2. Measure the Risk | Surface and score potential failure points | Clauses 6.4 – Risk identification, analysis, evaluation | Clause 6.4 – Risk assessment (6.4) | Measure |
| 3. Manage the Risk | Apply mitigations, control mechanisms | Clause 6.5 – Risk treatment | Clause 6.5 – Risk treatment | Manage |
| 4. Monitor in Real Time | Detect live failure signals and intervene | Clause 6.6 – Monitoring and review | Clause 6.6 – Monitoring and review | (Included in Manage + Govern) |
| 5. Improve & Adapt | Feed back post-deployment risks | Clause 6.7 – Recording and reporting | Clause 6.7 – Recording and reporting | Govern |
🧪 Phase 1: Map the Context¶
"You cannot manage risk you haven’t named."
Before writing any code, development teams must map the environment where the system will operate and define what failure would mean, for both users and society.
🔍 Risk Objectives:¶
- Identify where the system could cause harm
- Define vulnerable groups and power asymmetries
- Surface constraints (e.g., compliance, jurisdiction, societal trust)
🛠 Simulation – EqualMatch.ai:¶
- Workshop participants: product leads, fairness engineers, advocacy partners
- Key risks mapped:
- Underrepresented candidates being misranked
- Cultural mismatches in language or tone being penalized
- Prompted insight:
“This model is a gatekeeper. If we get it wrong, we reinforce the exclusion we aim to solve.”
🧪 Phase 2: Measure the Risk¶
"Without measurement, safety is just hope."
Abstract concerns must be converted into measurable risk scores to prioritize mitigation. Using a Likelihood × Impact (L×I) risk matrix, each potential failure is scored.
🔍 Risk Objectives:¶
- Transform assumptions into concrete failure scenarios
- Quantify severity and likelihood using real-world data
- Build a dynamic, living Risk Register
🛠 Simulation – EqualMatch.ai:¶
Table 16: EqualMatch.ai Risk Scenarios (Phase 2)
| Risk Scenario | Likelihood (L) | Impact (I) | Score | Category |
|---|---|---|---|---|
| Bias in resume ranking by name or dialect | 4 | 5 | 20 | Very High |
| Filtering out neurodiverse expression patterns | 3 | 4 | 12 | High |
| No explanation for rejection | 2 | 5 | 10 | High |
“Just because the model performs well on dev data doesn’t mean it’s safe in deployment.”
🧪 Phase 3: Manage the Risk¶
"The worst failures aren’t unpreventable, they’re unplanned for."
Each high-risk item must be addressed with design or process-level interventions. Mitigations should be assigned owners and tracked.
🔍 Risk Objectives:¶
- Design preemptive safety features (e.g., fallbacks, alerts, guardrails)
- Embed escalation paths for flagged outputs
- Ensure mitigation is measurable, owned, and enforced
🛠 Simulation – EqualMatch.ai:¶
Table 17: Risk Mitigation Strategies
| Mitigation Strategy | Assigned Team | Trigger Condition |
|---|---|---|
| Anonymize name fields during ranking | Engineering | Resume parsing initiated |
| Add Candidate Insights dashboard | Product + UX | Candidate receives rejection notification |
| Escalate low-confidence outputs to human review | Review Ops | Confidence < 0.6 or OOD language pattern detected |
“Public trust is a feature, not a postmortem.”
🧪 Phase 4: Monitor in Real Time¶
"The most dangerous AI is the one we stop watching after launch."
Post-deployment systems must detect risk signals and route them for immediate action. Monitoring must be designed into infrastructure.
🔍 Risk Objectives:¶
- Track drift, bias, anomaly, and failure indicators
- Build automated alerts and escalation trees
- Connect logs to downstream auditing systems
🛠 Simulation – EqualMatch.ai:¶
- Live fairness dashboard: match rates across race, gender, disability
- Auto-alerts: >30% disparity in interview referral rate
- Example event:
A community group posts that Black female applicants keep getting matched to customer service roles. Monitoring team confirms training data leak from biased job-tag corpus1.
🧪 Phase 5: Improve & Adapt¶
"Governance doesn’t end at launch, it begins there."
All signals from monitoring must feed into an improvement loop. Models should be retrained, risk scores updated, and audits traceable.
🔍 Risk Objectives:¶
- Post-incident learning → design updates
- Trigger model retraining or rollback
- Publish model card addendums and user-facing disclosures
🛠 Simulation – EqualMatch.ai:¶
- Action: Biased model version rolled back
- Added: Bias filter on new resume corpora
- Published: Audit log and apology message to user community
“Transparency is not just about publishing models. It’s about publishing how you fix them.”
Why This Matters¶
EqualMatch didn’t avoid failure by being perfect. It avoided it by designing for imperfection, by embedding foresight into every stage of its development.
"When AI makes high-stakes decisions, robustness isn’t optional. It’s operationalized trust."
This simulation shows how technical safety isn't just built during testing, it's architected across the lifecycle. From mapping who could be harmed to real-time alerts, the Risk-Lifecycle Framework turns governance from a compliance burden into an operational advantage2.
But managing visible risks is only half the story.
What about the failures that aren’t predictable?
What if the next risk doesn’t look like anything we've seen before?
To build truly robust AI, we must go beyond known risks and start measuring the unknown.
In the next section, we explore how uncertainty, confidence, and out-of-distribution behavior can be quantified, before they spiral into real-world harm.
Bibliography¶
-
Binns, R., Veale, M., Van Kleek, M., & Shadbolt, N. (2018). ‘It’s reducing a human being to a percentage’: Perceptions of justice in algorithmic decisions. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. https://doi.org/10.1145/3173574.3173951 ↩
-
Rahwan, I., Cebrian, M., Obradovich, N., Bongard, J., Bonnefon, J.-F., Breazeal, C., … & Wellman, M. P. (2019). Machine behaviour. Nature, 568(7753), 477–486. https://doi.org/10.1038/s41586-019-1138-y ↩