4.3.1. Bias Audits, Representation Metrics, and Fairness-by-Design
Bias Audits, Representation Metrics, and Fairness-by-Design¶
If an AI excludes you, mislabels you, or dehumanizes you: How would you feel? What went wrong?
In 2015, Google Photos labeled photos of Black people as “gorillas.”6 The issue wasn’t just technical, it was personal. It revealed a dataset that failed to represent Black individuals fairly, trained without balance, audited without care. Instead of fixing the bias, Google removed the label entirely, making the system blind to the very category it had misused.
This wasn’t just a software flaw. It was a design failure, a failure to ask who is seen, who is excluded, and how bias is encoded long before a model is deployed.
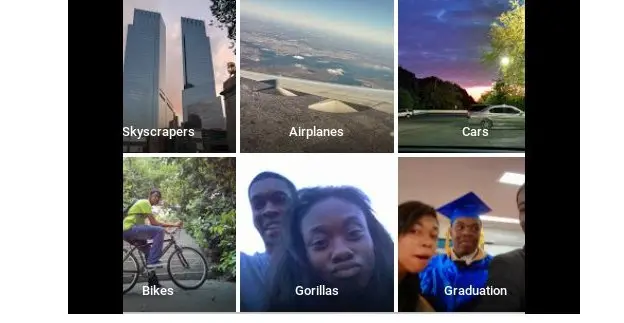
(Source)
🗞️ Google later apologized and removed the label. (BBC News, 2015)
Ask Yourself:¶
- How would you feel if your face was mislabeled by AI?
- Who does your dataset recognize, and who does it erase?
- Are your labels consistent across all groups, or shaped by assumptions?
- Are proxy features quietly encoding race, gender, or geography?
- If harm happens, can you trace it back, or will your dataset hide the source?
These choices expose a deeper reality: AI systems don’t just reflect bias, they operationalize it, knowingly or not, through every data decision made or overlooked.
These questions reflect real, measurable gaps in how datasets encode bias. And without structured analysis, these gaps stay hidden. That’s where (1) bias audits come in. They transform intuition and concern into evidence, offering a systematic way to reveal the disparities that shape AI behavior.
- A structured method to detect and quantify disparities in model behavior or dataset representation.
Diagnosing Bias: The Role of Audits¶
Bias audits provide the first layer of defense. They surface hidden disparities that might otherwise go unchallenged.
- Does the dataset overrepresent certain groups while underrepresenting others?
- Are labels consistent across subgroups, or do they reflect cultural assumptions?
- Do proxy variables (e.g., ZIP code, educational institution) encode protected characteristics like race or gender?
Such audits typically identify issues like:
- Class imbalance: Some groups are barely present in the data.
- Annotation inconsistency: Labels applied differently depending on who or what is being labeled.
- Latent correlations: Unintended associations between demographic variables and outcomes.
📘 ISO/IEC TR 24027:2021 recommends fairness assessments not only at the model output level, but also at the dataset level, especially for proxy bias and annotation consistency1.
Importantly, audits don’t solve bias, but they make it visible, and thus actionable.
But visibility alone is not enough. Once bias is surfaced, we need metrics to quantify who is present, who is missing, and how skewed that presence might be. This is where representation metrics come into play, moving from insight to structured evidence that can inform rebalancing, remediation, or even data rejection.
From Insight to Evidence: Representation Metrics¶
Knowing that a problem exists is only the beginning. The next step is quantifying it.
Representation metrics translate fairness into measurable dimensions, such as:
- Coverage: Are all key demographic groups present?
- Parity: Are they represented in proportion to their real-world presence?
- Completeness: Do all groups have equivalent feature quality and label richness?
Modern audits also consider intersectionality, not just “women” or “rural communities,” but “rural women under 30” or “Black veterans.” These combinations often reveal compounded underrepresentation that would be invisible in aggregate metrics2.

This conceptual visual shows how surface-level attributes like gender or race often dominate data analysis, while deeper intersectional identities, such as rural Black women or disabled Latinas, remain hidden and underserved. Just like an iceberg, the most dangerous and neglected aspects of data bias lie beneath the surface. AI generated Image
Bias Mitigation During Model Training¶
Once disparities are identified through audits and representation metrics, developers can apply targeted techniques during model training to reduce unfair outcomes. These include:
- Reweighting or Resampling: Adjusts training data distribution so that underrepresented groups receive proportional learning attention.
- Adversarial Debiasing: Trains an auxiliary model to detect sensitive attributes (e.g., race, gender) and penalizes the main model for encoding them3.
- Fairness-Constrained Optimization: Modifies loss functions to penalize performance gaps across demographic groups (e.g., equal opportunity, demographic parity)4.
These methods do not eliminate the need for better data, but they allow models to resist learning from spurious or biased correlations during training.
📊 Tool Spotlight: ReIn
ReIn is a dataset audit tool that uses cause-effect logic to detect fairness gaps early. Instead of merely checking statistical metrics, ReIn builds logical paths from metadata to uncover deeper structural imbalances.
- Generates feature-complete test cases
- Identifies “insufficient data” (using missing feature combinations)
- Flags overdominant causal chains where one feature unfairly drives decisions
- Calculates fairness indicators: bias, diversity, uniformity
📌 Source: 5.
🧪 Tool Spotlight: FairMT-Bench
FairMT-Bench is a benchmark designed to test long-term fairness in dialogue systems. It revealed that models which passed single-turn fairness tests often drifted into bias in extended interactions.
- Introduces turn-by-turn fairness tracking
- Penalizes stereotype reinforcement in follow-up responses
- Evaluates group-wise consistency across dialogue turns
📌 Takeaway: Fairness isn’t static. FairMT-Bench shows that bias can accumulate over time, and fairness must be designed to persist, not just tested once.
While FairMT-Bench focuses on language models, its approach still offers conceptual lessons for structured prediction tasks like credit scoring. The idea of monitoring fairness not just at model output, but across interaction patterns or decision chains is applicable when models adapt over time or learn from feedback loops, common in automated decision systems.
Tools like ReIn help uncover who is missing and why the model behaves that way. Without them, fairness is guesswork. With them, it becomes engineering.
✅ A dataset isn’t trustworthy because it looks fair. It’s trustworthy because it can be interrogated, corrected, and kept accountable, across tools, teams, and time.
In the next section, we shift from measuring fairness to managing trust long-term: through data lineage, curation practices, and ongoing stewardship.
TRAIn your brain: The Skewed Chatbot
Your chatbot works well in urban Korean dialects but performs poorly with elderly rural users. Error analysis reveals low representation of this group in the training data.
Tasks:
- Conduct a fairness audit plan using representation metrics: coverage, parity, completeness.
- What intersectional biases might remain invisible in aggregate metrics?
- Recommend one dataset-level solution based on fairness audits or representation scoring discussed in this section.
📌 Link to: Section 4.3.1 | Tools: ReIn | Standard: ISO/IEC TR 24027:2021
Bibliography¶
-
ISO/IEC TR 24027:2021. Artificial Intelligence, Bias in AI systems and AI-aided decision making. Geneva: ISO. ↩
-
Mitchell, M., et al. (2019). Model Cards for Model Reporting. FAT* Conference. https://doi.org/10.1145/3287560.3287596 ↩
-
Zhang, B. H., et al. (2018). Mitigating Unwanted Biases with Adversarial Learning. AIES. https://arxiv.org/abs/1801.07593 ↩
-
Zafar, M. B., et al. (2017). Fairness Constraints: Mechanisms for Fair Classification. AISTATS. https://arxiv.org/abs/1507.05259 ↩
-
Sivamani, S., Chon, S. I., & Park, J. H. (2020). Investigating and suggesting the evaluation dataset for image classification model. IEEE Access, 8, 173599-173608. ↩
-
Wired . When It Comes to Gorillas, Google Photos Remains Blind. https://www.wired.com/story/when-it-comes-to-gorillas-google-photos-remains-blind/ ↩