4.3.3. Can You Spot the Risk Before the Model Makes a Harmful Decision?
Can You Spot the Risk Before the Model Makes a Harmful Decision?¶
“Is it fair? Is it lawful? Is it safe to use?”
Between 2017 and 2019, the UK’s Department for Work and Pensions (DWP) rolled out an automated compliance analytics system within its Universal Credit program. By ingesting claimant work hours, benefit history, and self-reported earnings, the tool aimed to flag potential overpayments or non-compliance and trigger sanctions faster.
Issue: Automated Sanctions Disproportionately Harming Vulnerable Claimants¶
Thousands of claimants, especially disabled individuals and single parents, were falsely flagged as non-compliant, resulting in abrupt benefit reductions without adequate review.
Case Study 016: DWP Universal Credit Compliance Analytics Tool (Location: UK | Theme: Automated Sanctions & Fairness)
📌 Overview:
From 2017 to 2019, the UK’s Department for Work and Pensions introduced an automated system to review Universal Credit claims. The system analyzed work hours, benefit history, and reported earnings to detect possible overpayments and applied sanctions without delay.
🚧 Challenges:
The tool generated many incorrect flags because it interpreted normal variations in work and income as non‐compliance. Disabled claimants and single parents were hit hardest, since their earnings and work patterns did not match the majority. There was no required human review before sanctions, and neither claimants nor advisers could see why decisions were made.
🎯 Impact:
Thousands of families experienced sudden cuts to their benefits. Nearly one in three sanctions was later overturned on appeal, causing financial hardship and undermining trust in Universal Credit.
🛠️ Action:
In response, DWP began retraining the model each year with updated claimant data, added a mandatory human review step before any sanction was enforced, and published clear guidance on how the system worked and what criteria triggered a flag. Regular audits compared automated flags to manual reviews.
📈 Results:
After these reforms, the rate of wrongful sanctions fell by more than half. Appeals were faster and fewer, and both claimants and caseworkers reported improved confidence in the Universal Credit process.
Why It Happened¶
- High False-Positive Rate
The analytics model prioritized sensitivity over specificity, generating excessive non-compliance flags. - Data Bias Against Vulnerable Groups
Historical service data underrepresented disabled claimants’ episodic work patterns and single parents’ variable earnings, skewing predictions. - Lack of Human-in-the-Loop
Flags were routed directly to case managers, who often rubber-stamped sanctions under workload pressure. - Opaque Decision Criteria
Neither claimants nor advocates could inspect the algorithm’s logic or data thresholds, hampering appeals.
How to Solve It¶
The Five-Step Trust Audit
- Is there documentation and version control? (Lineage & Curation (4.3.2))
- Issue: No public data card or version log for the compliance model.
- Remedy: Publish a data card and model factsheet detailing training data sources, feature definitions, and update history (ISO/IEC 5259-3).
- Techniques & Methods: Data Card
- Data Cards are structured documentation artifacts that describe where the dataset came from, who created it, how it was labeled, and what limitations it carries (biases, legal boundaries, missing values, etc.).
- Unlike technical lineage tools, Data Cards capture human context: dataset purpose, known risks, assumptions, and consent status. No other tool links social intent to technical use this explicitly.
- Why it matters: DWP used cost as a proxy for health need. A Data Card would’ve flagged that logic gap before it was embedded in the model.
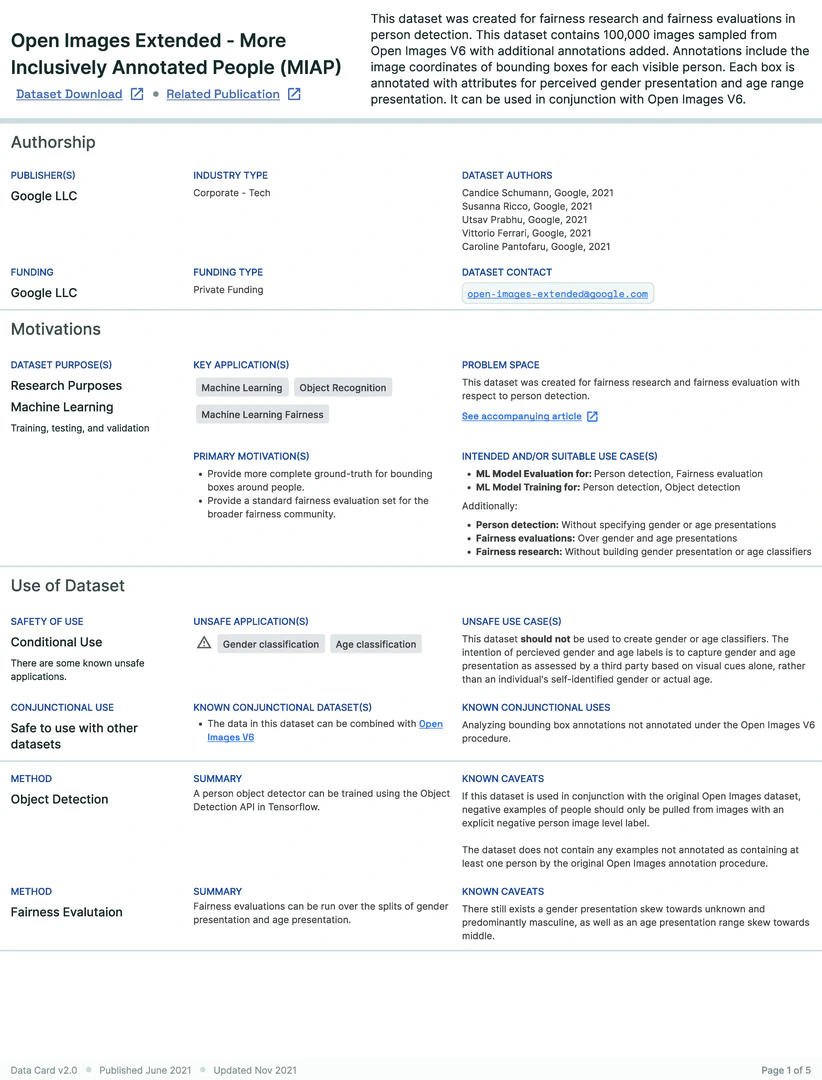
This data card, created by Google, outlines the structure, motivations, safety considerations, and known limitations of the MIAP dataset. It highlights responsible use for fairness evaluation in person detection tasks, while warning against unsafe applications like gender or age classification. The card exemplifies best practices in dataset documentation and transparency. (Source)
- Was a bias audit performed? (Bias Auditing & Representation Metrics (4.3.1))
- Issue: No formal fairness assessment across claimant subgroups.
- Remedy: Conduct intersectional bias audits using Fairlearn and Aequitas to measure disparate impact and error rates for disabled and single-parent demographics.
- Techniques & Methods: ReIn
- Rein Builds cause-effect graphs using dataset metadata and feature logic to simulate how groups are treated across decision chains.
- Unlike Fairlearn, which might miss conditional logic like “low income with variable hours,” ReIn simulates full decision chains, identifying when certain groups are systematically pushed into error paths due to feature interaction.
- Why it matters: At DWP, many disabled claimants were flagged because of rules tied to irregular earnings. ReIn could have traced how those flags emerged from biased logic, not biased labels.
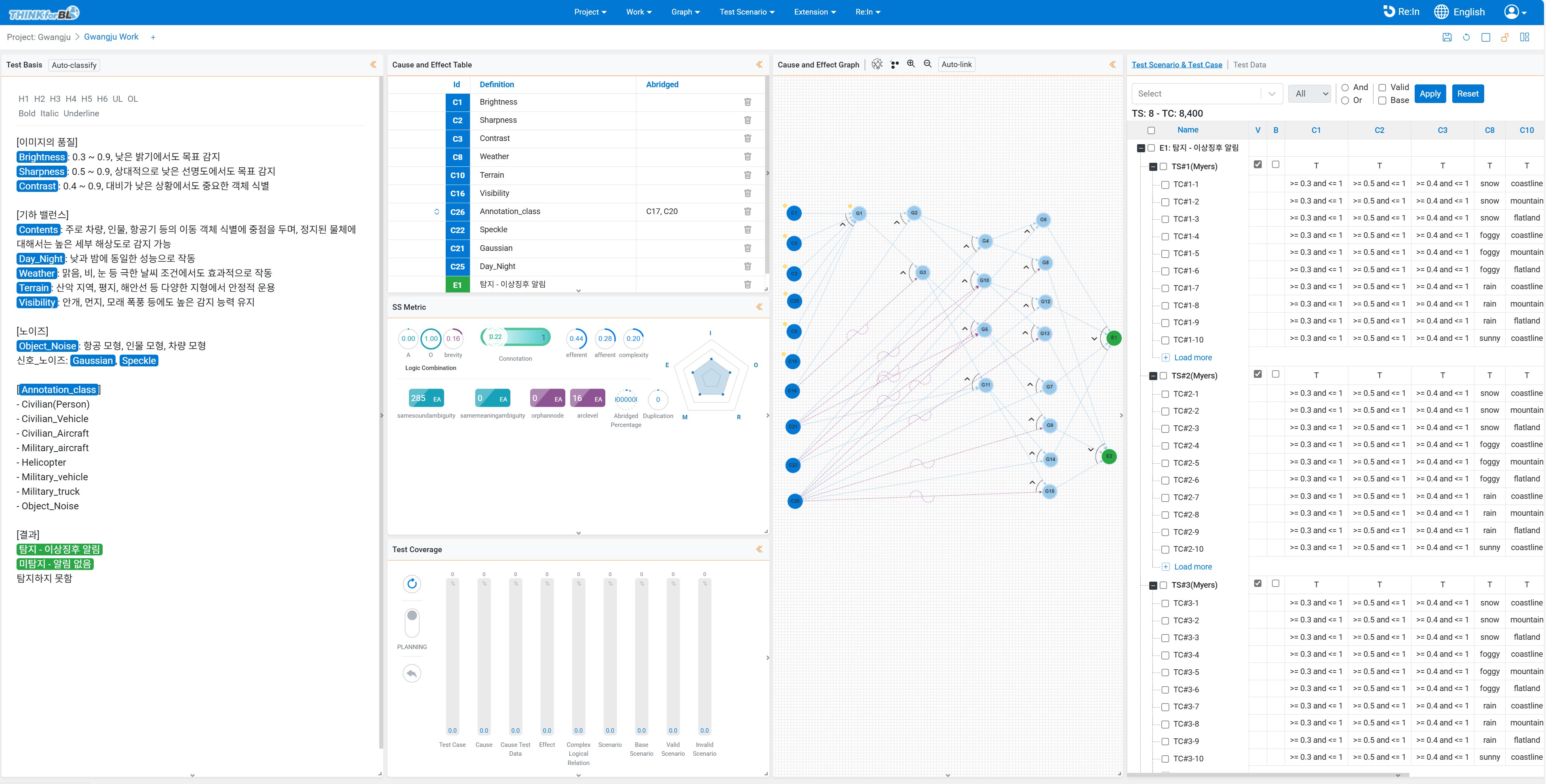
This screenshot from the REIN tool shows a structured cause-effect table and logic graph used to generate exhaustive, explainable test scenarios for visual data. The interface supports metadata reasoning (e.g., brightness, terrain, noise), and allows fairness coverage inspection across diverse environmental and object conditions.
- Can you trace the data? (Traceability & Metadata Integrity (4.3.2))
- Issue: Ingested records lacked provenance metadata.
- Remedy: Integrate lineage tracking (Apache Atlas, OpenLineage) for all data pipelines and annotate transformation steps in MLflow.
- Techniques & Methods: OpenLinage
- OpenLineage tracks how each dataset is transformed from source to final use, logging schema changes, join operations, missing value handling, etc. It creates a machine-readable audit trail.
- OpenLineage tracks data movement across services and tools, from ingestion to model output. Other systems log steps within a tool, this logs across the entire pipeline stack.
- Why it matters: In DWP, silent changes (like threshold updates or schema shifts) broke consistency. OpenLineage would log that drift automatically.
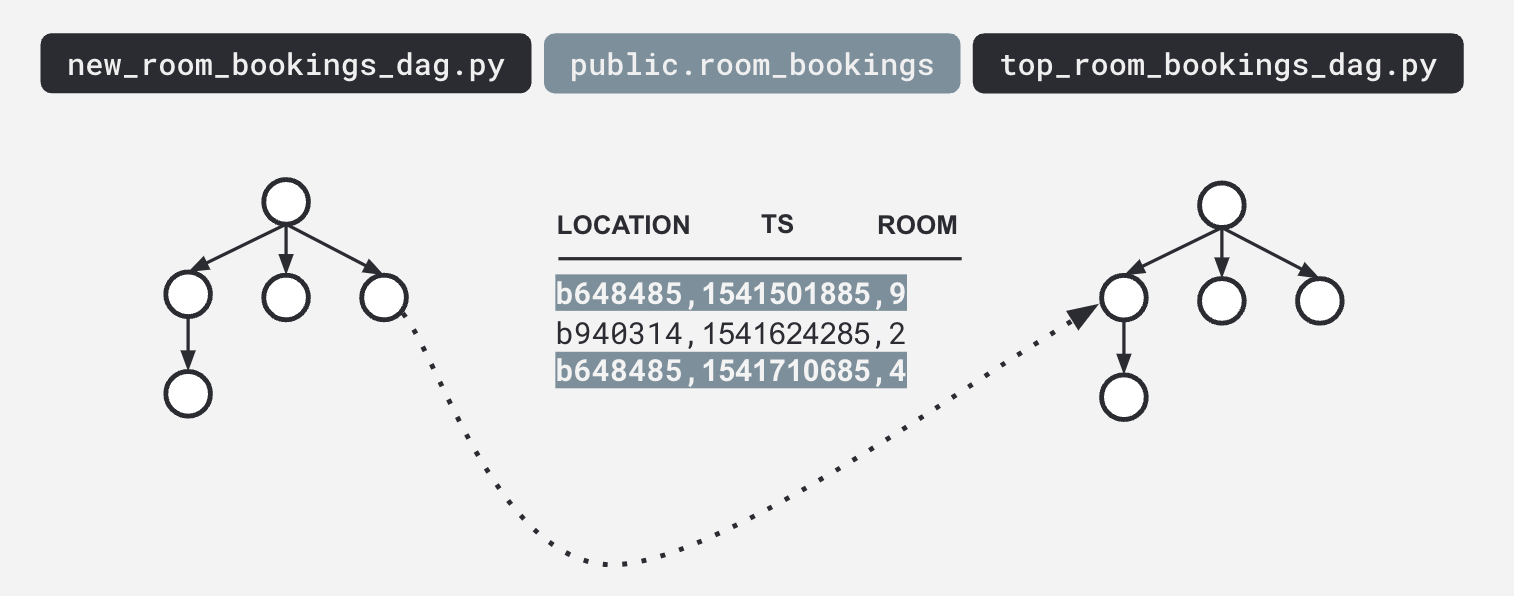
This illustration shows how data flows between different pipeline stages, from the `new_room_bookings_dag.py` script to the `top_room_bookings_dag.py`, with intermediate processing of the `public.room_bookings` dataset. Such lineage diagrams help trace data provenance and dependency relationships critical for auditability and governance. (Source)
- Have you stress-tested the impact? ( Feature Logic & Scenario Testing (4.3.1 + 4.3.2))
- Issue: No scenario testing for edge-case claimant profiles.
- Remedy: Simulate diverse claimant profiles (e.g., intermittent work, part-time earnings) with ReIn’s simulation engine and synthetic data generator (SDV) to reveal false-flag patterns.
- Techniques & Methods: SDV
- SDV learns the statistical patterns in the training data and generates synthetic records with controlled variations, allowing simulation of edge-case claimants that may be underrepresented.
- Unlike hand-crafted test cases, SDV creates statistically realistic but novel data, letting you simulate real-world edge cases without privacy risks or overfitting.
- Why it matters: DWP missed patterns of erratic work. SDV could simulate thousands of variable-income profiles to test model behavior before deployment.
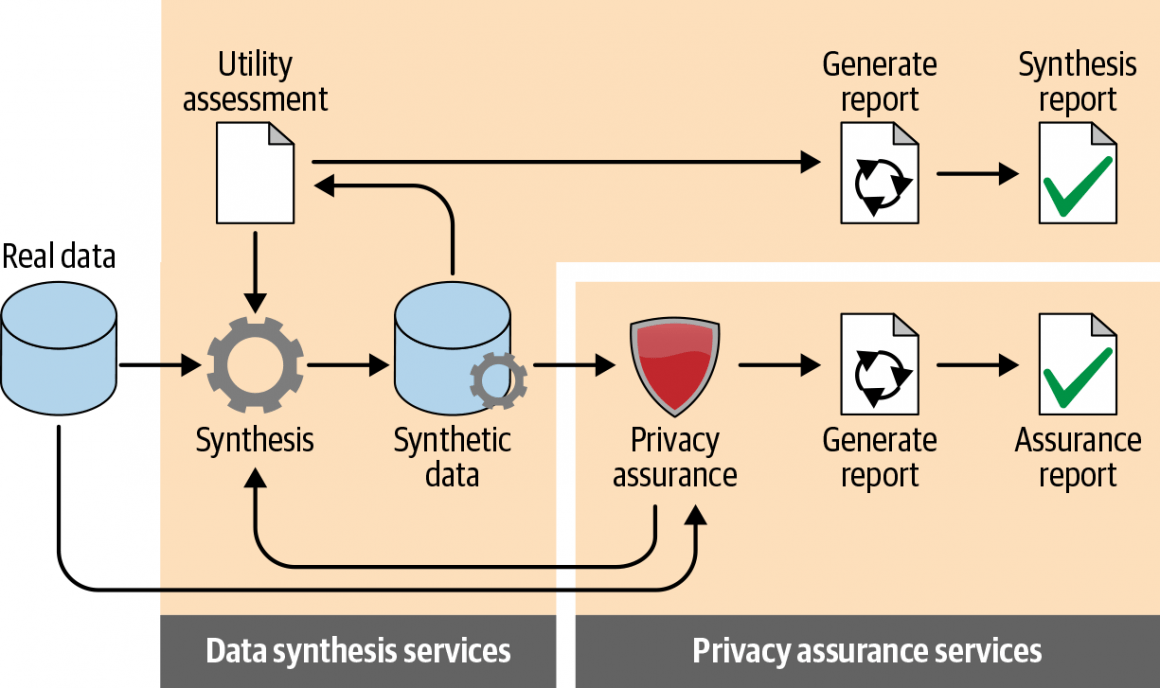
This diagram illustrates the lifecycle of synthetic data generation: real data is transformed through synthesis, then evaluated via utility assessment and privacy assurance. Each branch produces dedicated reports to validate both functionality and compliance, ensuring the synthetic dataset is both useful and privacy-preserving.
- Is there governance & human oversight? (Stewardship & Governance (4.3.2))
- Issue: Automated sanctions lacked a mandatory approval step.
- Remedy: Embed a human-in-the-loop checkpoint requiring case manager review and appeal logging (ISO/IEC 38505-1).
- Techniques & Methods: OPA
- OPA (Open Policy Agent) lets you define and enforce governance rules as code. For example: if user.disability == true then require_human_approval == true.
- OPA encodes rules like “must review disabled claimants” as executable logic, not documentation. It’s enforceable at runtime, not advisory after the fact.
- Why it matters: DWP lacked a formal review gate. OPA could block sanction actions unless specific rules (e.g., human review required) were met, baking accountability into execution.
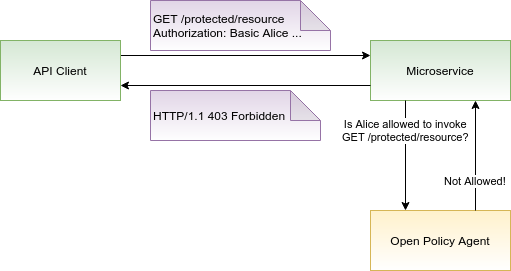
This diagram illustrates how Open Policy Agent (OPA) enables dynamic, policy-based access control. An API client requests access to a protected endpoint. The microservice consults OPA, which evaluates the policy and responds with a decision. In this case, the request is denied, and a 403 Forbidden response is returned. OPA separates policy logic from service code, making decisions explainable, auditable, and adjustable in real time.
Key Takeaway:
Embedding fairness in welfare algorithms demands transparency, bias testing, traceability, robust simulation, and enforceable human oversight to protect vulnerable populations.
TRAIn your brain: Welfare Sanctions Audit
You’re part of a parliamentary audit team reviewing an AI system that denied benefits to hundreds of disabled applicants. No one can explain why.
Tasks:
- Use the 5-Step Trust Audit from Section 4.3.3 to identify where failure occurred (documentation, bias, traceability, testing, oversight).
- Simulate how REIN or SDV could uncover subgroup harm before deployment.
- Propose governance code using OPA (e.g., mandatory human review for certain groups).
📌 Link to: Section 4.3.3 | Tools: ReIn, SDV, OPA | Standard: ISO/IEC 38505-1
In the next section, we’ll explore how continuous monitoring and feedback loops guard against unintended decay in data-driven social services.