4.4. What Happens When a Dataset Starts to Decay—And No One Notices?
What Happens When a Dataset Starts to Decay—And No One Notices?¶
Across the AI landscape, widely used datasets, like Reddit comments, Twitter sentiment corpora, and Stack Overflow text, are still powering the training and evaluation of modern models. Many of these datasets were scraped before 2019. Some go back as far as 2013.
That might not seem like a problem, until you realize the world those datasets reflect no longer exists.
In the years since, language has changed. So has context, platform culture, and public discourse.
Benchmarks like GLUE, Sentiment140, and Reddit-based sentiment corpora remain fixtures in NLP research. Yet studies from Stanford and the Allen Institute show that models trained on these datasets are less accurate, more brittle, and more biased when applied to post-COVID conversations.
- Terms related to mental health, identity, and public health are misclassified or misunderstood
- Slang, emoji use, and code-switching have evolved, but models trained on old data can’t follow
- Minority and younger demographics are underrepresented or invisibilized, especially in older Reddit and Twitter samples
So let’s ask: Are your AI systems still learning from a world that no longer exists?
🔬 Diagnostic Blindness: How Decay Undermines Health AI¶
This kind of decay doesn’t throw an error. It doesn’t crash your model or trigger alarms. The model keeps running. It still passes benchmark tests, because those benchmarks are stale too.
You may think your model is robust. But in reality, it’s trained on a pre-pandemic worldview, fluent in 2017, but dangerously naive in 2024.
📉 When Old Data Meets a New Crisis¶
During the COVID-19 pandemic, AI systems built on outdated datasets quietly failed. Not because of algorithmic errors, but because the world had changed, and the data had not.
-
Misinformation detectors trained on pre-COVID topics (e.g., anti-vax, Ebola) failed to flag early COVID conspiracies like “5G causes coronavirus” or “drink bleach to cure COVID.”
→ These claims circulated for weeks before being flagged, while satire and legitimate questions were wrongly suppressed. -
Content moderation tools misclassified peer support forums, especially around grief, anxiety, or long COVID, as toxic or harmful.
→ Language like “I can’t breathe” or “I don’t want to go on” was flagged out of context, leading to unjust penalties for mental health communities. -
Triage chatbots and symptom checkers failed to recognize key COVID patterns such as anosmia (loss of smell), fatigue clusters, or evolving long COVID vocabulary.
→ These symptoms didn’t exist in their training data. Entire patient profiles were misdiagnosed or dismissed.
❗ When health data doesn’t evolve with the world, models don’t just fail, they amplify harm.
Why Didn’t We Catch It?¶
Because the decay was invisible inside the pipeline. Benchmarks like GLUE, SST-2, or classic misinformation datasets hadn’t seen COVID either.
So models passed outdated tests but failed in real life.
Key causes:
- Missing terms and emergent health vocabularies
- Underrepresented COVID-era behavior and demographics
- Stale patterns in toxicity detection and symptom modeling
This is the kind of failure no precision score will surface, unless your data is actively refreshed and realigned with the world it’s meant to serve.
These failures usually take two forms:
- Drift , when the world changes but the data doesn’t
- Decay , when data quality erodes due to noise, gaps, or blind reinforcement
Together, they represent a quiet breakdown in trust.
1. Drift: When Data Falls Out of Sync¶
Even top-performing models become brittle when trained on static data. Data drift occurs when the statistical properties of input data change over time, making previously learned patterns less accurate or even misleading.
This drift can be gradual or abrupt, triggered by shifts in user behavior, market trends, seasonal events, or emerging vocabulary. Without detection and retraining, AI systems continue to act on outdated assumptions.
Real-world examples include:
- A healthcare model underestimating post-COVID respiratory cases
- A hiring algorithm favoring obsolete job skills
- A language model misunderstanding new social movements
NIST AI RMF 1.0 (2023) emphasizes that drift is a natural outcome in dynamic settings and requires active monitoring, not just static evaluation1.
2. Decay: When Data Quality Crumbles¶
Data decay refers to the gradual degradation of dataset integrity and representativeness over time. Unlike drift, which reflects changes in the world, decay reflects issues within the dataset itself, often invisible but deeply corrosive.
It can manifest as:
- Missing labels and inconsistent annotations
- Outdated samples no longer relevant to current populations
- Declining accuracy for minority or emerging subgroups
- Feedback loops, where errors or oversights become self-reinforcing
Decay results in AI systems learning from stale, biased, or corrupted information, undermining fairness, reliability, and compliance.
ISO/IEC 5259-3:2024 calls for ongoing validation and decay detection to ensure ethical model behavior over time2.
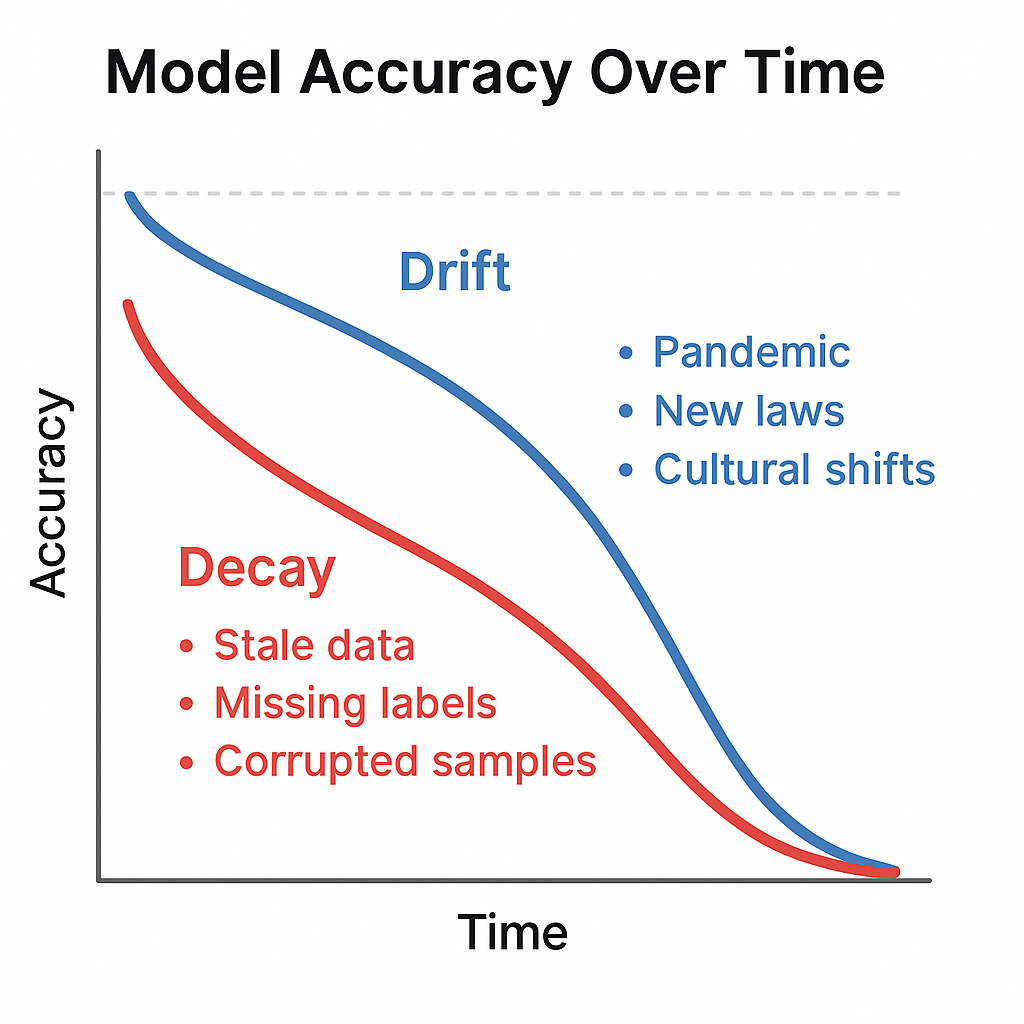
This graph illustrates how model performance can degrade over time. The initial accuracy remains high, but as the underlying data distribution shifts (drift) and data quality deteriorates (decay), accuracy gradually declines—highlighting the need for continuous monitoring and retraining. AI Generated Image
TikTok’s failure is not unique, it’s a warning. Data degradation happens silently and systemically. The challenge is not preventing change, but detecting it early and responding fast.
TRAI Challenge: Dataset Decay and Governance
Decide whether each of the following statements is True or False:
- Once a dataset is validated at launch, no further validation is needed.
- Missing labels or rising error rates in subgroups can be signs of dataset decay.
- Decay detection is part of the ISO/IEC 5259-2 standard.
- Feedback loops in recommendation systems are a form of structural decay.
- Metadata versioning and lineage tracking are unnecessary for post-deployment governance.
🧩 Refer to Section 4.4.1–4.4.3 for decay indicators, standards, and governance needs.
Bibliography¶
-
NIST (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). https://www.nist.gov/itl/ai-risk-management-framework ↩
-
ISO/IEC 5259-3:2024(E). Artificial Intelligence – Data quality for analytics and machine learning – Part 3: Data quality management process. ↩
-
Dhamala, J. et al. (2021). Brittle Benchmarks: How Social Biases Leak into NLP Models through Benchmark Datasets ↩
-
Bender et al. (2021). On the Dangers of Stochastic Parrots ↩
-
Roemmele et al. (2020). COVID-era Changes in Human–AI Sentiment Agreement ↩