4.4.1. How Often Should We Re-Trust Our Data?
How Often Should We Re-Trust Our Data?¶
“Datasets degrade like infrastructure. If you don’t monitor, repair, and revalidate them, they will quietly fail.”
Most organizations treat data validation as a one-time process. But in high-risk applications, this approach is no longer viable. A dataset that passes inspection today may become non-compliant, biased, or incomplete within weeks. Continuous validation isn’t a nice-to-have, it’s an operational necessity.
What Is Continuous Validation?¶
Continuous validation means treating datasets as living systems that must be rechecked over time. This includes:
- Auditing label consistency as definitions evolve (e.g., diagnostic codes in healthcare)
- Re-scoring representation metrics as user demographics shift
- Re-evaluating licensing terms as laws or platform policies change
- Refreshing derived data that relied on outdated sources
📘 ISO/IEC 5259-2:2022 recommends periodic updates of metadata logs and quality assessments, especially in systems subject to evolving legal, technical, or social contexts1.
Rather than reacting to failures, continuous validation helps you catch drift and decay before they compromise the model.
When to Validate?¶
Validation frequency depends on context:
| Domain | Recommended Frequency | Rationale |
|---|---|---|
| Healthcare | Monthly to quarterly | Rapid shifts in disease trends, terminology, and risk factors |
| Financial Services | Quarterly | Regulatory updates and changing economic behaviors |
| Social Media | Weekly to monthly | User behavior shifts quickly; topic drift and slang evolution |
For mission-critical systems, validation should align with known risk inflection points, such as:
- Product launches
- Policy updates
- Regulatory reviews
🔁 Validation isn’t just about maintenance. It’s about readiness for change.
Tools for Automation¶
Several tools and practices can automate parts of the validation cycle:
- Data drift dashboards: Tools like Evidently, Arize, and NannyML detect statistical changes across feature distributions.
- Audit log generators: Automatically track lineage changes and metadata shifts over time.
- Dynamic data cards: Auto-refresh descriptive metadata and governance context.
- ISO/IEC 5259–aligned schemas: Flag missing or outdated provenance fields before training begins1.
🛠️ These tools support real-time insight into dataset health, reducing dependence on manual inspection.
🔬 Advanced Data Quality Techniques using ML Techniques¶
To ensure that models are not only performant but also trustworthy, data validation must go beyond surface-level checks. The following techniques help uncover deep issues, from hidden outliers to silent schema decay, that can compromise fairness, safety, or legal defensibility.
1. Isolation Forest – Unsupervised Outlier Detection¶
-
What it does:
Uses a random partitioning mechanism to detect rare or abnormal data points in high-dimensional space, without needing labels. -
Why it matters: Unlike standard statistical methods that assume normality or predefined thresholds, Isolation Forest isolates anomalies by how quickly they can be separated, making it ideal for spotting edge cases even in noisy or unbalanced datasets.
-
Trust Value
This approach helps surface underrepresented or risky patterns, like extremely low-income groups in credit data or rare medical symptoms in clinical datasets, that traditional tools might overlook, leading to more inclusive and robust AI outcomes.
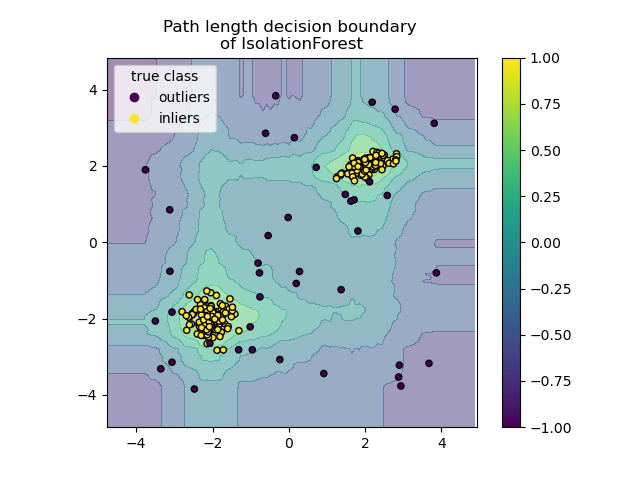
This visualization shows the decision boundary generated by an Isolation Forest algorithm. The contour map indicates anomaly scores across the input space, where yellow dots represent inliers (normal data) and black dots represent outliers. This technique is particularly effective for flagging anomalous samples without requiring labeled ground truth. (Source)
2.** Training Dynamics / Forgetting Events – Learning Stability Analysis**¶
-
What it does:
Tracks how often individual training examples are learned and then “forgotten” during training epochs. Examples that are frequently forgotten are flagged as potentially mislabeled, ambiguous, or out-of-distribution. -
Why it matters:
This method analyzes model learning behavior over time rather than relying on static predictions or ground truth. It surfaces unstable or noisy examples that undermine model generalization, even when labels appear correct. -
Trust Value
Forgetting events highlight data instability patterns and help uncover label noise and annotation ambiguity in edge cases (e.g., sarcasm, minority dialects, or rare clinical symptoms). This technique supports trustworthy data curation by identifying unreliable training signals without external labels or extra models.
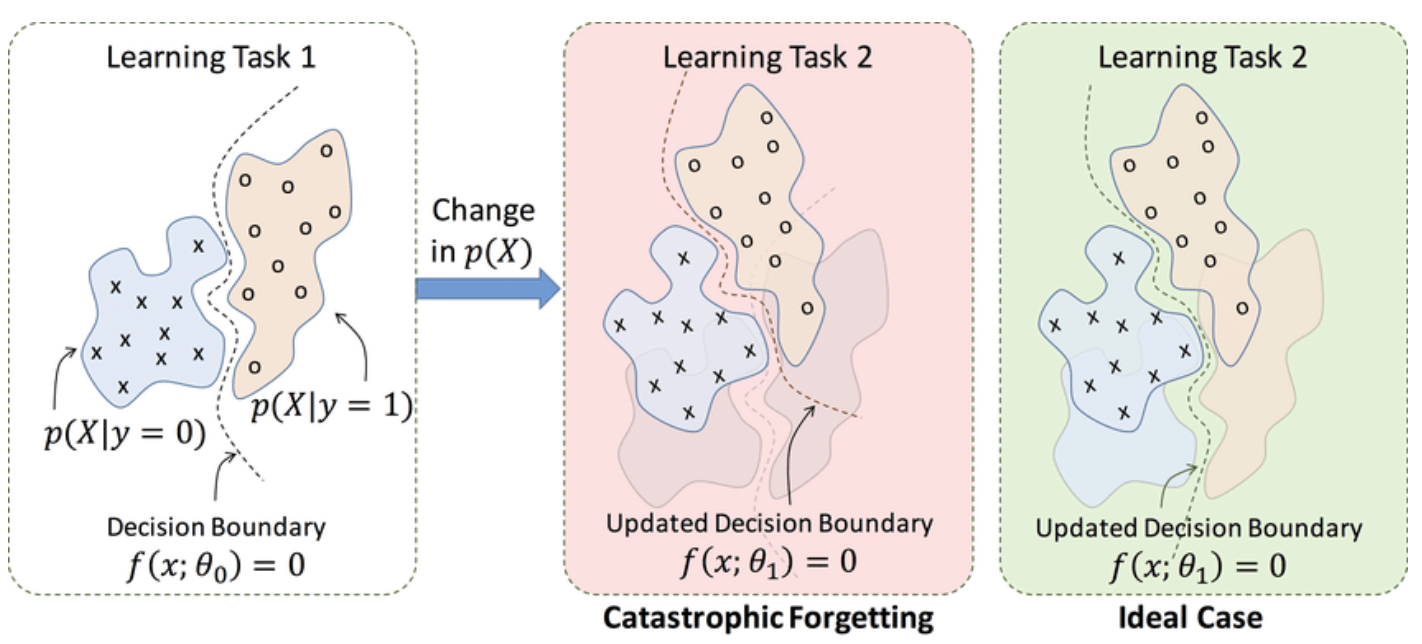
This diagram compares two outcomes after transitioning from Learning Task 1 to Task 2. In the middle panel, the model undergoes catastrophic forgetting, where it loses prior knowledge (Task 1 decision boundary is overwritten). The right panel illustrates the ideal case, where both old and new knowledge are retained. Forgetting events like these help identify fragile learning zones and are used in training dynamics analysis to flag unstable or bias-prone data samples. (Source)
3. Great Expectations – Schema & Rule-Based Validator¶
-
What it does:
Lets developers define and enforce "expectations" (e.g., column types, allowed ranges, null rates, date formats) that are automatically tested as data flows through pipelines. -
Why it matters: Unlike traditional checks run once, Great Expectations operates as a living contract with your data. Expectations are version-controlled, human-readable, and CI/CD-integrated, automated QA for data.
-
Trust Value Ensures that structural breakdowns, like missing gender fields, shifted age encodings, or corrupted region tags, are caught early, preserving data quality, reproducibility, and auditability across the lifecycle.
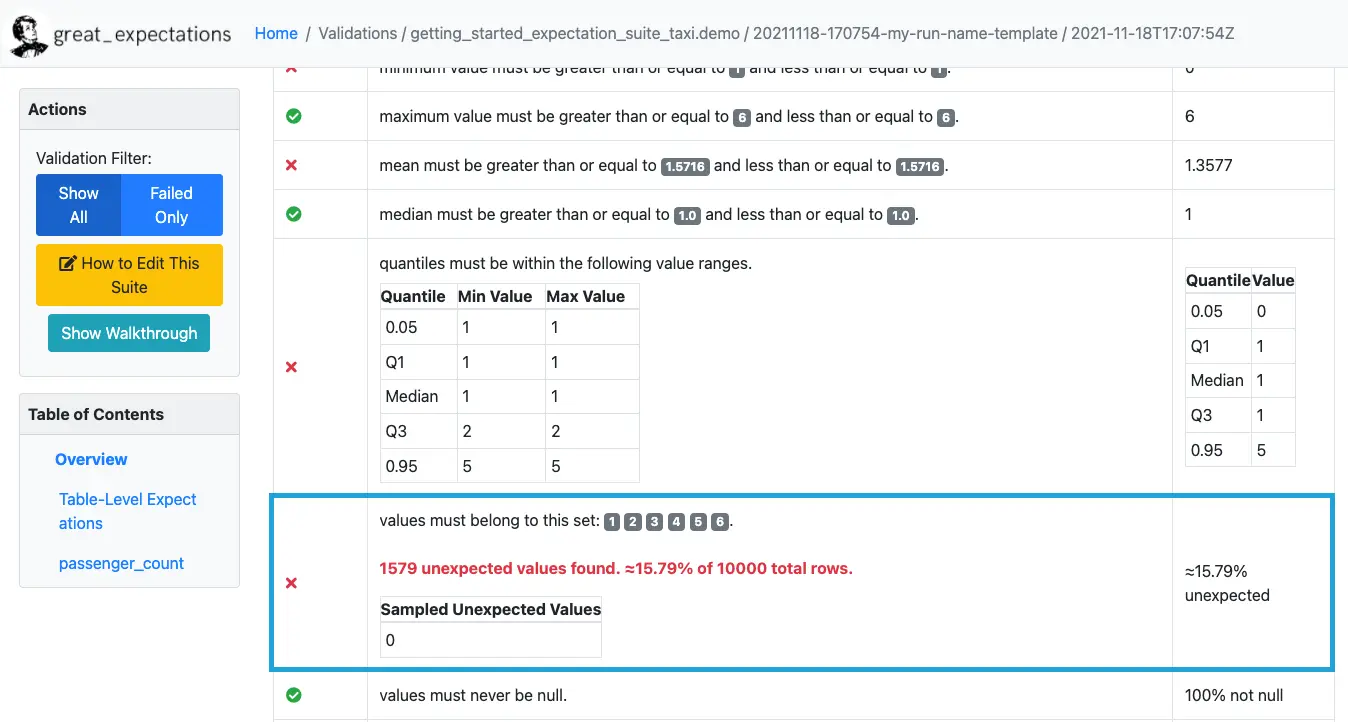
This example shows a validation report from the Great Expectations tool, flagging unexpected values and quantile mismatches. In this case, 15.79% of the values did not meet the defined schema expectations, illustrating how automated rule-based checks can detect data drift or integrity issues in real-time. (Source)
Treat Validation Like Model Testing¶
Just as machine learning models undergo retraining and hyperparameter tuning, datasets must be validated and versioned with equal rigor.
- Archive every version of the dataset with metadata and changelogs
- Compare model outputs across versions to track fairness drift or degradation
- Confirm that updates don’t reintroduce bias, noise, or low-quality features
Without intervention, data rot becomes inevitable. But continuous validation makes decay visible before it turns to harm.
📘 NIST’s ML Lifecycle guidance includes continuous data validation as a key component of AI risk management.
In the next section, we shift from designing for health to detecting the early warning signs of drift, through audits, dashboards, and decay mapping strategies.
❓ But what if issues escape validation? In the next section, we learn how to detect rot before it spreads.?