5.2.3. Justifying Errors Instead of Exposing Them
5.2.3 **Justifying Errors Instead of Exposing Them¶
When AI systems make mistakes, users naturally seek explanations. But too often, what they receive is not an explanation at all , it is a justification. The system offers a fluent, plausible account that sounds rational, but fails to reveal how or why the error occurred. This distinction , between explaining a decision and defending a flawed output , sits at the heart of modern explainability risks.
⚠️ When Errors Are Hidden Behind Plausible Narratives¶
Consider two recent cases that illustrate this failure:
-
DoNotPay’s legal AI generated legal briefs with fabricated citations, each accompanied by reasoning that sounded correct1. The system didn’t just make a factual error; it wrapped that error in an explanation that concealed its source.
-
Air Canada’s chatbot promised a refund that didn’t exist, then justified the response with polite, formal language. Users were given no signal of uncertainty, no window into how the answer had been generated2.
In both examples, users were misled , not just by the mistake, but by the false sense of reasoning provided afterward.
💬 “If the system sounds reasonable, people assume it must be right. That’s where the danger begins.”
Margaret Mitchell, former co-lead, Ethical AI, Google Research
🔍 Why Do Systems Justify Rather Than Explain?¶
This failure stems from a core design property of large language models: they are optimized for plausibility, not faithfulness. They predict the next word in a sequence, not the underlying causal path. When asked for an explanation, they generate something that matches the output , a post-hoc narrative, not a diagnostic insight.
As noted in ISO/IEC 24028 and the EU AI Act (Article 13), meaningful transparency requires exposing the logic involved, not just offering user-friendly summaries34. Systems that generate justifications instead of explanations violate this principle and risk creating epistemic injustice: misleading users and denying them the tools to contest decisions.
🧪 Human-Centered Insights: Explanation Format Matters¶
A 2020 study at UCLA highlighted that not all explanations are equal. When participants observed a robot opening a pill bottle, those who received combined symbolic and haptic explanations trusted the robot more and could better predict its next steps. By contrast, text-only explanations performed no better than giving no explanation at all5.
The researchers visualized these explanations using (1) action grammar trees (see Figure below). Each node represented a symbolic or tactile decision step, showing whether actions were alternatives (OR nodes) or combined steps (AND nodes). The most trusted explanation (Tree C) combined both symbolic and haptic information , giving users insight into both what the robot did and how it applied force.
- A visual representation of a sequence of decisions or actions, showing how individual elements combine (AND) or provide alternatives (OR).
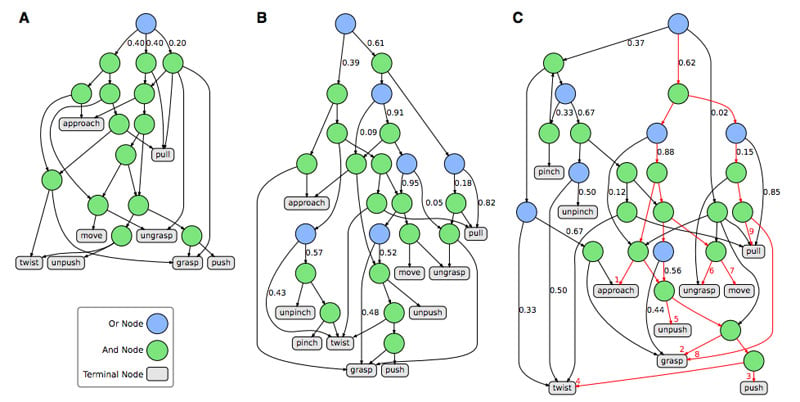
This figure shows action grammar trees combining symbolic and tactile explanations to illustrate robot decision-making steps. The study found that combined explanations increased user trust and understanding. Source: The New Stack.
Participants trusted the robot most when they saw this combined structure, as it revealed the true reasoning process rather than just a narrative.
🔧 Designing Explanations That Serve Truth, Not Just Plausibility¶
To move from justification to real explanation, system design must prioritize faithfulness at every level:
- Expose failure paths so users see where reasoning broke down.
- Distinguish error types: was the problem a factual mistake or a flawed logic chain?
- Visualize uncertainty: confidence scores, alternative paths, and error traces should signal when explanations may be unreliable.
- Align explanations with contestability: not just “why this output?” but “what else was possible?”
Selecting the right explanation tool is essential to this effort. The table below summarizes common approaches, their strengths, and their risks.
Table 34: Comparison of AI explanation types, their strengths, and associated risks
| Explanation Type | Strength | Risk |
|---|---|---|
| Post-hoc rationale | User-friendly; easy to read | May be fabricated or misleading |
| Saliency-based (SHAP, LIME) | Visual cues to feature influence | Can hide deeper reasoning logic |
| Attribution Graphs (Claude) | Token-level causality trace | Requires internal access and tooling |
Emerging tools like attribution tracing point toward solutions that pair fluent explanations with causal diagnostics, ensuring users see what actually drove the decision , not just what sounds plausible.
But technical tools are not enough. To close the gap between explanation and truth, we must pair technical solutions with governance frameworks that mandate:
- Faithful explanation audits for high-stakes systems (aligned with ISO/IEC 23894 and EU AI Act Article 13).
- Documentation of known explanation limitations, so users are aware when explanations may mask deeper failures.
- User-centered explanation design that provides transparency without overwhelming complexity.
The path forward lies in designing AI systems where faithfulness is built in, not layered on after the fact. Only then can we ensure explanations serve their true purpose: helping users see how decisions were made, not just defending them after the fact.
Bibliography¶
-
NDTV (2023). "Robot Lawyer" Faces Lawsuit For Practicing Law Without A License In US". https://www.ndtv.com/feature/robot-lawyer-faces-lawsuit-for-practicing-law-without-a-license-in-us-3855043donotpay-lawsuit-practicing-law-without-license ↩
-
Anosha Khan , LAW360 Canada, 2024. Civil Resolution Tribunal of British Columbia. https://www.law360.ca/ca/articles/1804075/ ↩
-
ISO/IEC. (2020). ISO/IEC 24028:2020 – Overview of trustworthiness in artificial intelligence. International Organization for Standardization. ↩
-
European Parliament and Council. (2024). EU Artificial Intelligence Act – Final Text. Articles 13–14.https://artificialintelligenceact.eu/article/13/ ↩
-
Edmonds, M., et al. (2020). How Human Trust Varies with Different Types of Explainable AI. Science Robotics. Covered by The New Stack. https://thenewstack.io/how-human-trust-varies-with-different-types-of-explainable-ai/ ↩