5.3.1. Diversity Without Context Can Still Be Harmful
5.3.1 **Diversity Without Context Can Still Be Harmful¶
In response to bias concerns, many organizations have rushed to include more “diverse” data in their model training pipelines. More ethnic names. More languages. More faces. On paper, it looks fair. But what happens when that diversity is stripped of meaning, when the symbols of difference are included, but the systems still fail to understand them?
This is where fairness fractures. Not in representation alone, but in interpretation.
⚠️ What Happened?¶
Case Study 018: 2020 Twitter Image Cropping Bias (Location: Global | Theme: Fairness and Representational Bias)
🧾 Overview
In 2020, Twitter’s automated image cropping algorithm was found to favor white faces over Black faces, and men’s faces over women’s, when selecting image previews. The model failed to align with human expectations of fairness and visibility.
🚧 Challenges
The system focused on what it defined as “salient” without understanding social context or inclusion, leading to biased outputs despite diverse input data.
💥 Impact
The bias sparked public backlash and forced Twitter to reassess its AI practices and remove the auto-cropping feature.
🛠️ Action
Twitter discontinued the cropping algorithm and committed to more transparent and inclusive AI evaluations.
🎯 Results
The case showed that diversity in input data alone does not prevent bias without context-aware design.
In 2020, Twitter’s automated image cropping algorithm came under scrutiny when users discovered that it consistently favored white faces over Black faces, and men’s faces over women’s. Despite exposure to diverse visual inputs, it repeatedly cropped images to center certain identities, ignoring others, even when both were equally prominent in the frame.
This failure became highly visible when users shared a photo containing both Barack Obama and Mitch McConnell. Despite Obama being equally or more prominent, the algorithm repeatedly cropped the image to center on McConnell’s face. The model’s definition of “salience” failed to align with human perception or social context, showing how inclusion without understanding leads to harm.
The model wasn’t malicious. It had been trained to focus on what it deemed “salient.” But it failed to grasp the social meaning of visibility, presence, and inclusion. Adding more diverse faces didn’t help, because the system still lacked a contextual understanding of what mattered. This wasn’t a data exclusion problem. It was a context erasure problem.
Similar failures in hiring, credit scoring, or healthcare risk systems can turn this invisibility into direct exclusion, from jobs, services, or life-critical interventions.
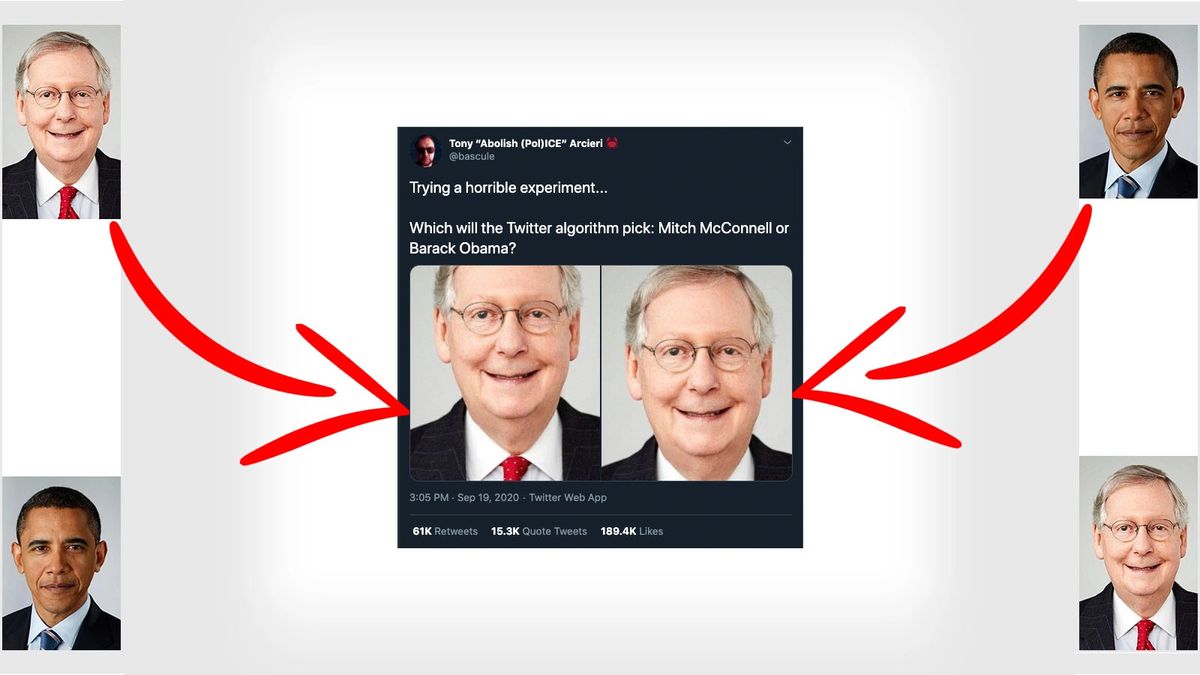
This image became a viral demonstration of how inclusion without understanding can lead to representational harm.
A system that includes everyone, but understands no one, isn’t inclusive. It’s decorative diversity with statistical bias.
❓ Why Did It Happen?¶
Modern AI systems learn from co-occurrence, not comprehension. They associate patterns with outcomes, often without grasping social meaning or historical discrimination embedded in those patterns. Including more demographic tokens, or in this case, more diverse faces, doesn’t make the model fair if those features are still misinterpreted or negatively weighted.
This is a form of indirect discrimination, recognized in anti-discrimination law: when a seemingly neutral system disproportionately harms a protected group by relying on features that act as proxies for group identity. Even if a model treats all features “equally,” those features may still encode systemic disadvantage.
That’s why the EU AI Act requires high-risk systems in domains like employment or public services to demonstrate not just statistical parity, but the absence of discriminatory feature proxies, especially where decisions affect fundamental rights. The Korean AI Basic Act mandates documentation of group-level performance disparities, including subgroup dropout, false positive asymmetries, and unintended feature impact. The OECD AI Principles emphasize robustness against bias “not just in data selection, but in data interpretation.” These legal frameworks recognize what technologists sometimes miss: inclusion is not understanding.
Bias Types in Context: Twitter Image Cropping Case
The Twitter image cropping failure reflects multiple forms of bias:
-
Algorithmic bias: Bias arising from the system’s design or optimization logic that systematically disadvantages certain groups.
-
Representational bias: When certain groups are underrepresented, misrepresented, or marginalized in the model’s outputs, even if present in the data.
-
Measurement bias: Bias embedded in how features (e.g., “salience”) are defined, measured, or operationalized, leading to harm.
-
Indirect discrimination: A form of legal bias where neutral rules disproportionately harm a protected group by relying on features that act as proxies for identity.
Understanding the type of bias at play helps identify how fairness failed , and where interventions are needed.
🔧 How to Detect and Correct This Failure¶
Fixing this problem requires context-aware evaluation, not just data balancing. Methods include:
Table 35: Techniques for detecting and correcting fairness failures in AI systems
| Technique | Purpose | Notes |
|---|---|---|
| Subgroup Performance Audits | Track metrics across identity intersections | E.g. not just “gender,” but “non-binary + foreign-educated” |
| Counterfactual Testing | Replace identity features and compare output changes | Reveal hidden proxies and impact of irrelevant terms |
| Concept Activation Vectors | Measure if latent space encodes harmful stereotypes | Common in NLP and vision bias audits |
| Semantically Annotated Datasets | Include role, context, sentiment labels | Prevents token-level or pixel-level misclassification |
This table summarizes evaluation and auditing methods that help uncover hidden biases and ensure fairness reflects social and contextual realities. These strategies help move fairness from surface metrics to semantic sensitivity, so models don’t just see difference, but respect it.
Diversity in input doesn’t guarantee fairness in outcome. Without context, inclusion becomes tokenization.
Next, we explore what happens when these failures go undetected, not just causing social harm, but endangering lives, especially in risk prediction systems in healthcare and finance.
Bibliography¶
-
BBC. (2021). Twitter finds racial bias in image-cropping AI. https://www.bbc.com/news/technology-57192898 ↩