5.4.1. Design Strategies for Hallucination and Misleading Output Control
Design Strategies for Hallucination and Misleading Output Control¶
💬 “We see today that those systems hallucinate, they don't really understand the real world.” Yann LeCun, Meta’s Chief AI Scientist
Can you trust an answer that sounds right, but isn’t?
The problem with hallucination isn’t just that the model makes something up. It’s that the output sounds correct, arrives with confidence, and provides no signal to the user that something’s wrong. The real risk lies in the invisible mismatch between fluency and fidelity, when the answer is smooth, but the logic behind it is shaky, missing, or entirely fabricated.
THINKBOX: Fluency vs Fidelity
👉 Fluency is how smoothly and convincingly AI presents its outputs — polished language, confident tone, or natural phrasing.
👉 Fidelity is how accurately those outputs reflect the true internal reasoning of the model.
📌 Key takeaway:
Fluency can mask flaws. A system may sound convincing but hide faulty or fabricated logic. Trustworthy AI demands fidelity — outputs that show what truly happened inside the model.
🧠 Why Do Models Hallucinate?¶
Large language models are trained to predict the next token given prior context, not to fact-check or verify. Even when fine-tuned with instruction-following or reward feedback, the model still builds on patterns, not ground truth.
Hallucinations occur most often when:
- The model receives ambiguous or open-ended prompts
- The training data contains conflicting or shallow facts
- The decoding algorithm (like top-k or nucleus sampling) prioritizes novelty or diversity
- There’s no internal mechanism to abort or defer when uncertainty is high
In Claude 3.5, Anthropic researchers found that hallucinations emerge when the model suppresses its default refusal behavior, for example, when asked about a fictional person like “Michael Batkin.” A misfired “known entity” feature triggered a confident but fabricated answer instead of the model’s usual refusal1. 1.
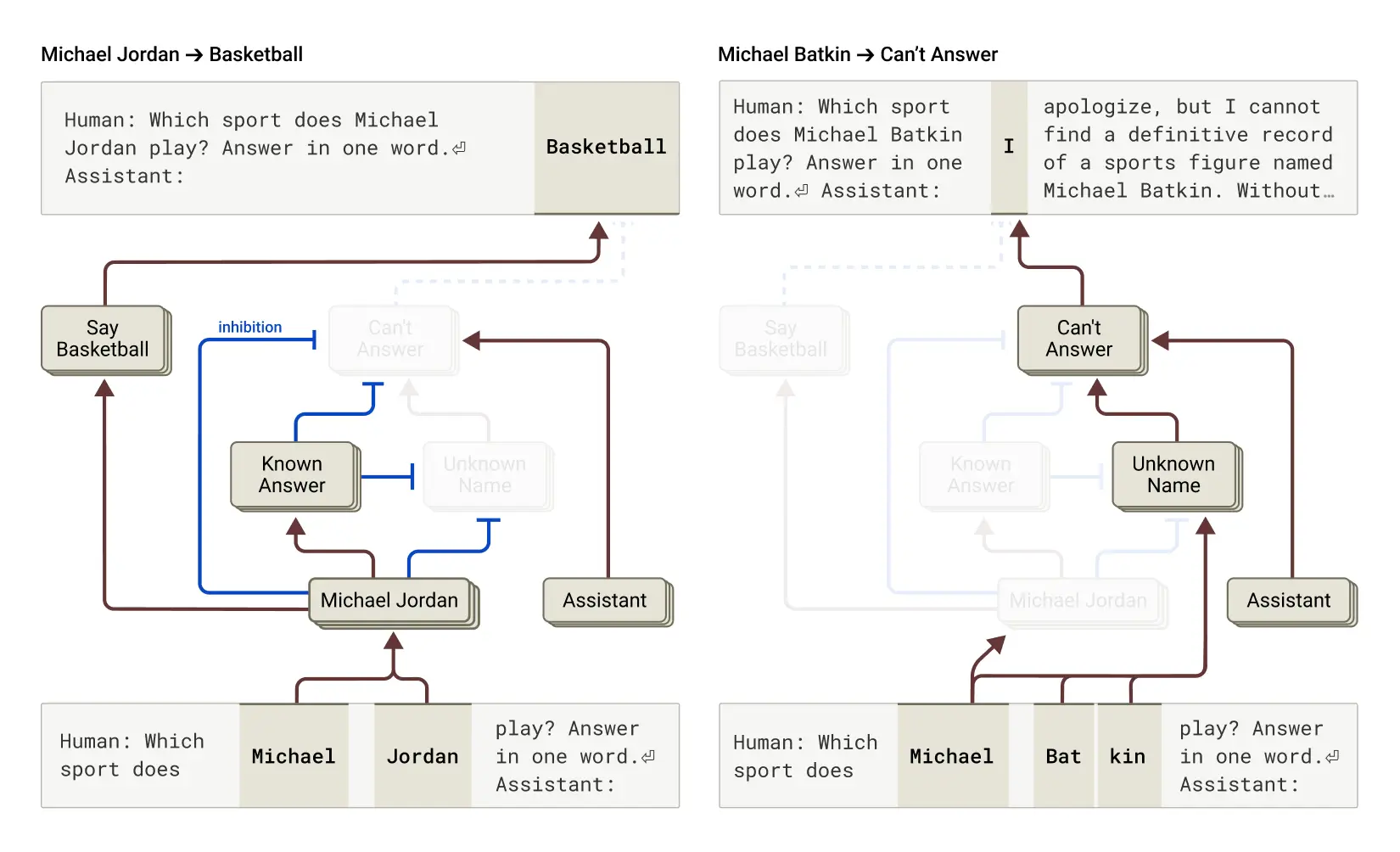
This figure from Anthropic’s interpretability research shows attribution graphs tracing how Claude processes a known query (Michael Jordan → Basketball) versus an unknown query (Michael Batkin → Can’t Answer). The graph visualizes internal reasoning pathways that lead to either a confident response or an appropriate refusal. Source: Anthropic.
Trustworthy Design Guidance
ISO/IEC 42001:2023 (Clauses 6.1, 8.1, Annex B) requires organizations to implement documented risk controls, verification processes, and fallback planning across the lifecycle. These provisions support safeguards against erroneous outputs and traceability, but do not prescribe exact strategies.
🛠️ How Do We Mitigate Hallucination Risk?¶
The solution isn’t just tuning the model, it’s a design architecture that intervenes at multiple points: prompt intake, generation strategy, uncertainty expression, and post-output auditability.
🔧 Model-Level Mitigation Strategies¶
Table 37: Design strategies for controlling hallucinations and misleading outputs in AI systems
| Strategy | Description | Risk Controlled |
|---|---|---|
| Refusal Tuning | Train the model to say “I don’t know” | Hallucination under uncertainty |
| Uncertainty Regularization | Penalize confident outputs on low-likelihood paths | Overconfident hallucinations |
| Knowledge Grounding | Anchor outputs to verified documents or APIs | Unverifiable responses |
| Chain-of-Thought Guardrails | Detect if reasoning steps match actual activations | Rationalization drift |
This table summarizes techniques that improve model alignment with truthfulness and reduce the risk of overconfident, unverifiable, or fabricated outputs.
ChatGPT Hallicination legal case
In the 2023 ChatGPT legal case (Schwartz v. Avianca, Inc.), a U.S. attorney submitted a court filing generated by ChatGPT, which included hallucinated case citations, nonexistent precedents presented with confident language and plausible logic1. The AI did not refuse or indicate uncertainty, leading the lawyer to trust and file the fabricated material. The court sanctioned the attorney, highlighting the risk of over-reliance on fluent but unverified AI outputs.
Systems like Claude 3.5 attempt to mitigate such risks by defaulting to refusal on unfamiliar prompts. But even these safeguards can fail under prompt pressure or misfired triggers, showing the need for stronger refusal bias and explicit uncertainty signaling2.
❓ Design Reflection:
Does your system make it easier to believe, or to verify?
Trustworthy AI requires contestability by design.
Designing for doubt helps guard against unintentional harm , but what about harm by design? Next, we explore how attackers exploit models’ very strengths to produce dangerous, deceptive outputs with precision.
Bibliography¶
-
Anthropic. (2025, March). Tracing the Thoughts of a Large Language Model: Interpretability in Claude 3.5. https://www.anthropic.com/news/claude-3-5 ↩↩↩
-
ISO/IEC. (2023). ISO/IEC 42001:2023 – Artificial Intelligence – Management System. International Organization for Standardization. ↩