5.4.2. Breaking the Model to Break the Trust – Adversarial Attacks That Fool With Precision
Breaking the Model to Break the Trust – Adversarial Attacks That Fool With Precision¶
Most people turn to AI for help. But some come looking for cracks. Not to smash the system, but to understand it too well.
Adversarial attacks don’t break AI by force. They break it by precision: tiny, carefully crafted inputs that twist the model’s logic, flip decisions, or trigger harmful behavior , all without raising alarms. The system keeps working. The output looks polished. And trust unravels, often before we realize what’s happened.
🎯 What Are Adversarial Attacks?¶
The U.S. National Institute of Standards and Technology (NIST) defines adversarial machine learning as “the manipulation of a model’s behavior through carefully crafted inputs that exploit weaknesses in the model's design or training data”1.
Originally exposed in computer vision , where imperceptible pixel changes can cause object detectors to label a stop sign as a speed limit , adversarial examples now target text, multimodal, and recommendation systems alike.
In image models, these attacks can: - Cause object detectors to misidentify hazards (e.g., stop sign as speed limit) - Trigger misclassification in medical imaging (e.g., benign lesion flagged as malignant) - Fool biometric systems (e.g., face ID unlock with adversarial patterns)
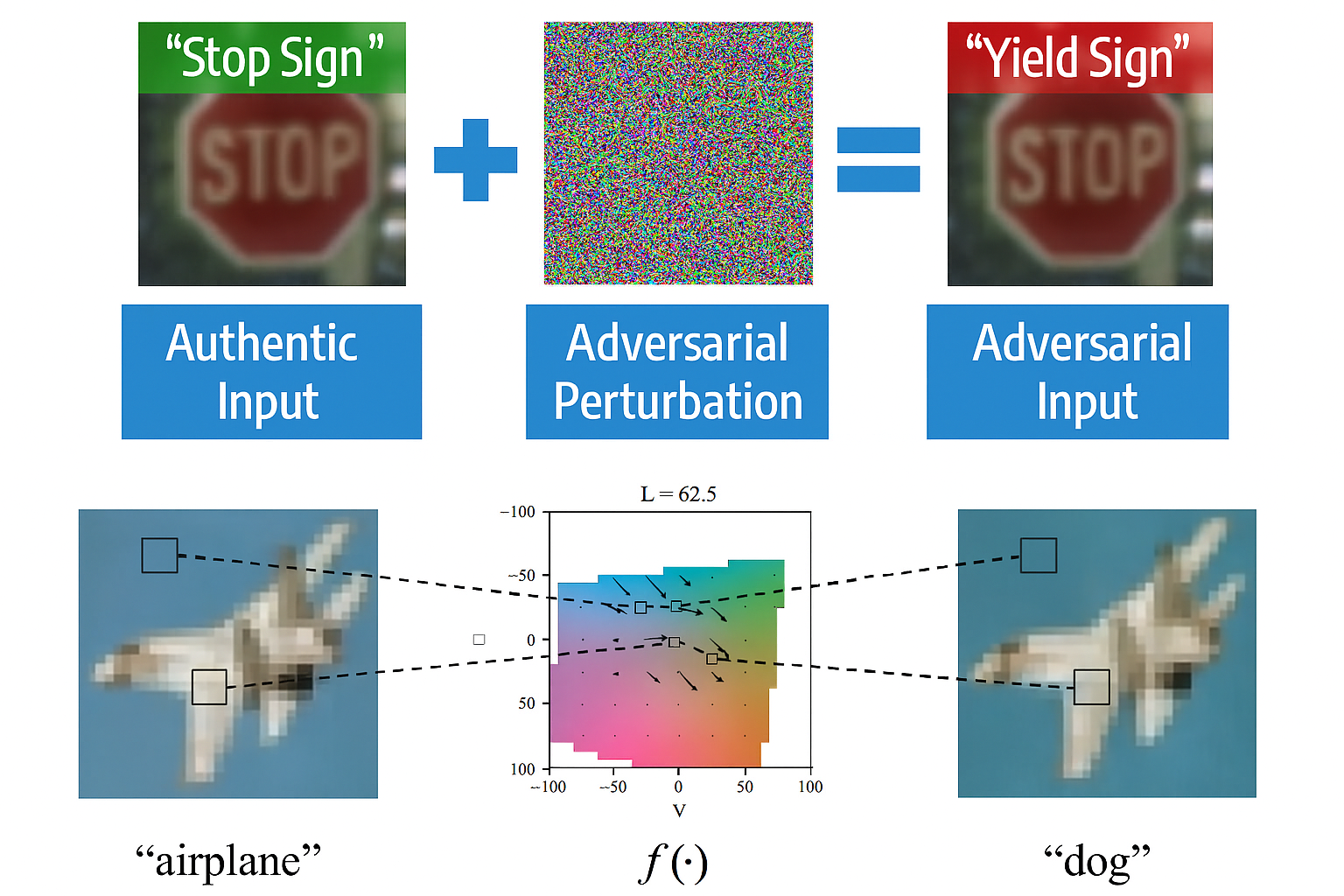
This figure shows how adversarial perturbations cause machine learning models to misclassify images. A stop sign is misclassified as a yield sign, and an airplane image is misclassified as a dog. The examples illustrate the vulnerability of vision models to small, targeted input changes. Source: dx.doi.org/10.36959/643/306.
In language models, they may:
- Cause toxic or misleading outputs in safe contexts
- Mislead intent recognition through subtle prompt manipulation
- Produce deepfake text, voice, or media indistinguishable from authentic content
Both domains share a chilling truth: fluency, clarity, or accuracy at the surface can mask deep manipulations underneath. This last case is no longer theoretical. The rise of deepfake generation, ultra-realistic fake videos, cloned voices, or AI-generated images, demonstrates a different kind of adversarial threat: not to the model’s internal logic, but to the trust users place in its outputs. From synthetic political speeches to impersonated executive audio used in financial scams, these outputs weaponize model fluency to erode verification boundaries in the real world.
🧪 How These Attacks Work¶
Adversarial attacks exploit non-robust features , patterns models learn that correlate with outputs, but lack true semantic meaning. Whether in pixel space or token space, these weaknesses become footholds for attackers.
Table 38: Overview of adversarial attack vectors in AI systems
| Attack Vector | Description | Example |
|---|---|---|
| Pixel Perturbation | Tiny pixel tweaks fool vision models | Stop sign → speed limit, face spoofing for unlock |
| Input-Level Perturbation | Slight phrase change misleads language models | Typos trigger toxic completions |
| Prompt Injection | Hidden commands in benign-looking text | HTML-embedded override text |
| Data Poisoning | Malicious samples inserted during training | Backdoor triggers in image or text classification |
| Generative Abuse | Hyperrealistic deepfakes or synthetic outputs | Fake medical scans, political speeches, cloned voices |
The table highlights common methods attackers use to manipulate models across modalities
🧭 Risk Management Alignment:
ISO/IEC 23894:2023 (Annex A.11) identifies adversarial attacks as a key risk source and requires risk treatment to reduce such risks relating to system concerns over security2.
🔐 Techniques for Adversarial Defense¶
Defending vision models and LLMs alike requires recognizing modality-specific challenges , and designing layered safeguards.
Table 39: Overview of defense techniques in AI systems.
| Defense Technique | Description | Limitation |
|---|---|---|
| Adversarial Training | Expose model to attack patterns during training | Limited generalization beyond known attacks |
| Input Sanitization | Preprocess or filter input to reduce attack success | May degrade clean input performance |
| Gradient Masking | Obscure optimization paths attackers rely on | Can reduce interpretability, fragile under adaptive attacks |
| Watermarking / Forensics | Detect synthetic or deepfake outputs | May not generalize across all fake types |
| Cross-modal Verification | Use text-image alignment to cross-check outputs | Resource intensive, complex to design |
The table summarizes defense strategies designed to mitigate these risks and their respective limitations.
❓ Ethical Reflection:
When adversarial attacks fool medical AI or public safety systems, who answers for the harm?
Accountability depends not just on model strength , but on whether systems were designed and deployed with robust, multimodal defenses and continuous monitoring.
TRAI Challenges: Minimal Adversarial Test on MNIST

Scenario:
You want to verify how a small pixel-level change could fool a simple MNIST digit classifier. Your goal is to apply a tiny noise pattern and see if the prediction changes.
🎯 Your Challenge:
1️⃣ Load a pretrained MNIST model (e.g., torchvision.models or any simple CNN).
2️⃣ Add a small uniform noise pattern: noise = torch.rand_like(img) * 0.01
3️⃣ Classify the original and noisy image.
4️⃣ Report whether the prediction changed.
👉 Reflect:
- How small was the noise needed to fool the model?
- Why does this demonstrate model sensitivity? (See Section 5.4.2)
💡 Minimal code snippet:
# Example noise injection
noisy_img = torch.clamp(img + torch.rand_like(img) * 0.01, 0, 1)
pred_orig = model(img).argmax(1).item()
pred_noisy = model(noisy_img).argmax(1).item()
print(f"Original: {pred_orig}, Noisy: {pred_noisy}")
Now, we examine the other side of the coin: Can simple language prompts defeat even the safest models? And if so, how do we prepare for the next wave of prompt-based jailbreaks?
-
U.S. National Institute of Standards and Technology (NIST). (2023). Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations. NIST Special Publication 1270. https://doi.org/10.6028/NIST.SP.1270 ↩
-
ISO/IEC. (2023). ISO/IEC 23894:2023 – Artificial intelligence — Risk management. International Organization for Standardization. ↩