7.3.1. When Trust Decays in Silence
When Trust Decays in Silence¶
“The model didn’t fail suddenly. It failed slowly, while everyone stopped paying attention.”
AI systems rarely break overnight. Most failures begin as subtle shifts: a small data mismatch, an overlooked group in retraining, or a societal norm the model no longer reflects. Over time, these discrepancies don’t just degrade accuracy, they erode fairness, ethical alignment, and most critically, user trust.
Yet few oversight systems are built to detect this decay.
Risk boundaries that made sense at launch often become outdated. Thresholds calibrated for yesterday’s conditions fail to catch today’s harms. And even when user feedback is collected, it too often disappears into disconnected logs or unstructured inboxes, never informing model updates.
This isn’t a failure of algorithms. It’s a failure of attention.
Consider a hypothetical scenario:
A large financial institution deploys an AI model in 2020 to assess small business loan applications. At launch, the model clears fairness and performance audits based on pre-pandemic data. But as gig and delivery workers surge into the economy post-2021, the model, trained primarily on traditional small business owners, fails to adapt.
Because retraining cycles focused only on predictive performance, the model quietly learns to deprioritize applications from gig-sector applicants. By 2023, approval rates for these applicants have dropped by 38%. No alert is triggered. No review is launched. Fairness drift goes unnoticed, not because the system is malicious, but because oversight was never designed to evolve.
This is a maturity problem in performance monitoring.
Many organizations still operate at low levels of oversight maturity, tracking latency or accuracy, but overlooking drift, representational fairness, or subgroup degradation. The following table outlines how oversight evolves with organizational maturity:
Model Monitoring Maturity Levels
| Level | Description | Oversight Capability |
|---|---|---|
| 0 – Static | No post-launch monitoring beyond uptime | No visibility into drift or fairness |
| 1 – Reactive | Monitors performance metrics only (e.g., accuracy) | Detects changes, but lacks context |
| 2 – Proactive | Includes drift detection and subgroup analysis | Supports fairness and relevance tracking |
| 3 – Integrated | Links monitoring to feedback and model updates | Enables dynamic governance and retraining |
A system stuck at Level 1 might flag lower accuracy. A Level 3 system would explain who is affected, why, and escalate the issue to reviewers who can intervene.
Thinkbox
 “Not all drift is model drift.”
“Not all drift is model drift.”Many monitoring tools track input distribution drift (e.g., data shifts), but miss fairness drift:
- The model still performs overall
-
But subgroup accuracy or rejection patterns shift significantly
A Stanford HAI study (2022) found 80% of retrained models introduced new subgroup disparities even when overall performance improved.
Fairness drift monitoring requires: -
Subgroup-aware metrics
- Trigger thresholds for drift-based retraining audits
- Use of tools like Fairlearn, Aequitas, or REIN
Regulatory Shift Toward Evolving Oversight¶
Standards frameworks are beginning to demand this evolution.
- ISO/IEC 5259-2:2024 introduces data quality indicators for drift detection, representativeness, and coverage tracking over time1.
- The NIST AI Risk Management Framework (2023) calls for lifecycle-based monitoring that measures “fitness-for-purpose” over time, not just at launch2.
You don’t monitor to protect the model. You monitor to protect the people it affects.
Thinkbox
“Performance stability ≠ fairness stability.”According to a 2022 study by Stanford HAI, 80% of retrained models preserved overall accuracy while introducing new subgroup disparities, because performance drift was monitored, but fairness drift was not3.
OECD AIM: Monitoring the World in Real Time¶
One system leading the way in post-deployment oversight is the OECD AI Incidents and Hazards Monitor (AIM). This infrastructure processes over 1,000 daily AI-related news items to detect, cluster, and analyze risks from deployed systems across the globe4.
It distinguishes between:
- Incidents – actual cases of harm
- Hazards – emerging signs of potential failure
Its pipeline uses multi-stage LLMs, metadata tagging, and a four-day update buffer to track how real-world systems fail in unexpected ways.
Drift-Aware Monitoring in AIM
| Feature | Functionality |
|---|---|
| Multi-stage LLM filtering | Classifies events as incident, hazard, or irrelevant using GPT models |
| Metadata enrichment | Adds domain, geography, stakeholder, and impact context |
| Clustering engine | Groups related events to detect systemic trends |
| Recall buffer | Captures updates over several days to avoid premature conclusions |
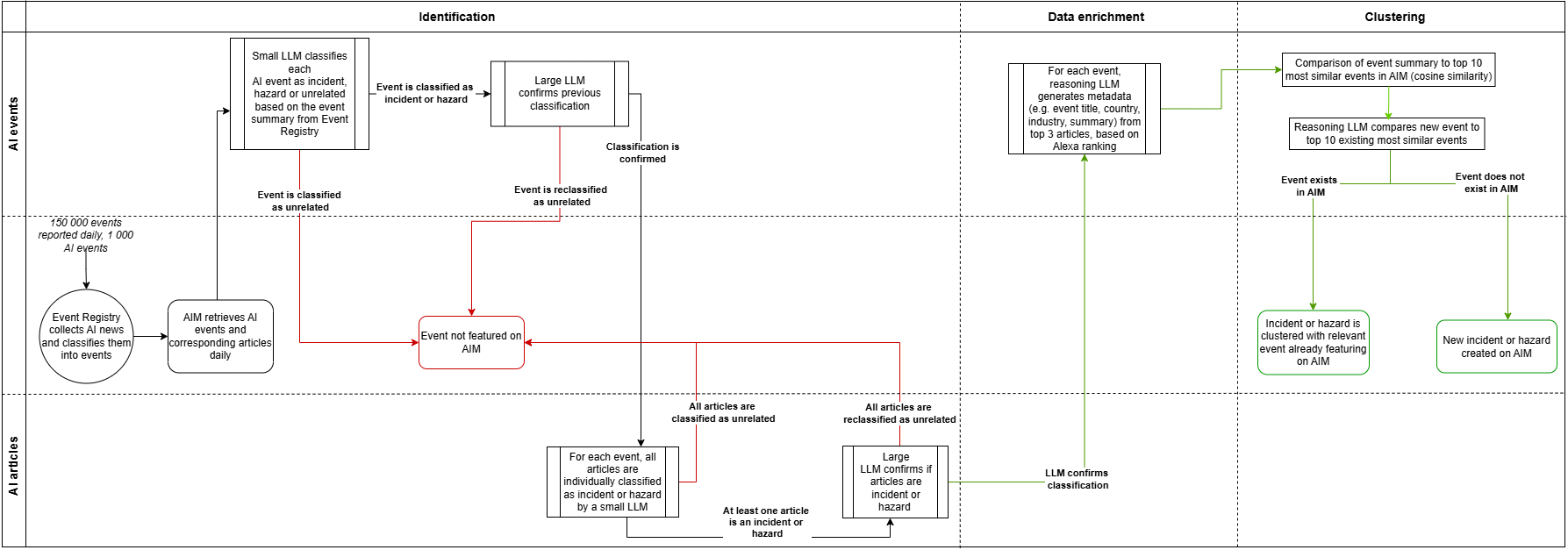
This figure illustrates the OECD AIM system’s architecture for clustering and monitoring AI-related incidents and hazards using LLM pipelines. Source: OECD.AI.
Oversight isn’t about catching failures after they happen. It’s about noticing trust decay before anyone gets hurt.
Bibliography¶
-
ISO/IEC. (2024). ISO/IEC 5259-2: Data quality , Part 2: Quality evaluation indicators for AI training data. https://www.iso.org/standard/81229.html ↩
-
National Institute of Standards and Technology. (2023). AI Risk Management Framework 1.0. https://www.nist.gov/itl/ai-risk-management-framework ↩
-
Raji, I. D., et al. (2022). The Misalignment of Model Updates: The Forgotten Risk of Concept and Fairness Drift. Stanford HAI. https://hai.stanford.edu/news/how-model-updates-hurt-fairness ↩
-
OECD.AI. (2025). AI Incidents and Hazards Monitor. https://oecd.ai/en/aim ↩